A colleague Bill Wardlaw (Robert Steinberg’s 2nd PhD student, I believe) retired recently and I was offered his office. I thought “this will be a nice chance to clean out all the junk I’ve accumulated” and started the move yesterday. You know those boxes that reams of xerox paper gets delivered in? I had 12 of those boxes filled with preprints, many unsorted – not counting the piles of papers which were on top of the boxes because I was too lazy to put them in. I resolved to throw away every paper I had not looked at in the past two years or I had a copy of electronically.
I started with a random box and managed to toss some papers out before running across an old, very well-worn xerox copy of Hejhal’s “Selberg’s trace formula and the Riemann zeta function” (published in the Duke Math J, but I forgot the year). I could not make myself throw it away! I had these intense memories of the times I loved reading it. In fact, I’ve read that paper several times and loved it each time. I realized I loved that paper too much to trash it. A little extreme since it was just a xerox copy but I just figured I’ll just save that one paper.
Back to work, I trashed several more papers and eventually came across some mimeographed notes of A. Weil, signed by Weil himself. I can’t throw away a piece of mathematical history! By the way, my memory of things is that I got these papers by being assigned Larry Goldstein’s old office at the University of Maryland (I was there for 1 year after graduating in 1983 and LG had just retired), who cleaned out his office but left a few old preprints assuming they would be trashed I guess. The reason LG had them was because he somehow inherited some papers of Robert Mountjoy. I remember hearing that RM died in a traffic accident on his way from Princeton, where he had a postdoc, to the University of Maryland, where he was going to start a tenure track job. I remember hearing that Mountjoy was a student of Andre Weil but according to the math genealogy project, he was a student of Saunders MacLane. In any case, he graduated from the University of Chicago in 1964 and Weil left Chicago for the IAS in 1958, so Weil could not have been his official advisor. Mountjoy got these papers from Weil himself. Now I have them and, to me, they are priceless. They remind me of the 2 times I met Prof Weil. One was a party given by V. Chari and the other was a dinner at an India restaurant with V. Chari, A. Weil and myself. Weil knew VC because he once spend some time in India where he became close friends with VC’s father. I remember he gave me the problem of trying to generalize his proof of quadratic reciprocity using Eisenstein series of the 2-fold metaplectic cover of SL(2) to prove higher reciprocity using n-fold covers. I never was able to solve his problem (I think it is still unsolved) but will never forget his kindness (nor VC’s, though she was young herself too at the time) towards a very young and very green postdoc. So, I cherish and treasure those preprints and could never throw them away either.
Are you starting to see the pattern? To make a long story short, I started with 12+ boxes and, at the end of the process, ended up with 7 boxes. There are too many papers I either love now or have strong memories of the time I enjoyed reading them. Some were just beautifully written, some full of extraordinary ideas, and some just astonishing for their display of shear mathematical wizardry.
I guess I’m a mathematical romantic.
 denote the largest
denote the largest 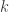 such that there exists a [
such that there exists a [ ]-code in
]-code in 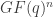 .
. be a sequence of linear codes with parameters [
be a sequence of linear codes with parameters [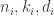 ] such that
] such that  as
as  , and such that both the limits
, and such that both the limits 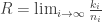 and
and  exist. The Singleton (upper) bound implies
exist. The Singleton (upper) bound implies  .
. denote the set of all
denote the set of all ![(\delta,R)\in [0,1]^2](https://s0.wp.com/latex.php?latex=%28%5Cdelta%2CR%29%5Cin+%5B0%2C1%5D%5E2&bg=ffffff&fg=323232&s=0&c=20201002) such that there exists a sequence
such that there exists a sequence  , of [
, of [ and
and 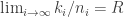 .
.![\alpha_q:[0,1]\to [0,1]](https://s0.wp.com/latex.php?latex=%5Calpha_q%3A%5B0%2C1%5D%5Cto+%5B0%2C1%5D&bg=ffffff&fg=323232&s=0&c=20201002) , such that
, such that is strictly decreasing on [
is strictly decreasing on [ ],
], ,
,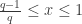 then
then  ,
,![\Sigma_q=\{(\delta,R)\in [0,1]^2\ |\ 0\leq R\leq \alpha_q(\delta)\}](https://s0.wp.com/latex.php?latex=%5CSigma_q%3D%5C%7B%28%5Cdelta%2CR%29%5Cin+%5B0%2C1%5D%5E2%5C+%7C%5C+0%5Cleq+R%5Cleq+%5Calpha_q%28%5Cdelta%29%5C%7D&bg=ffffff&fg=323232&s=0&c=20201002) .
.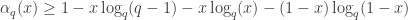 . In other words, for each fixed
. In other words, for each fixed 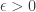 , there exists an [
, there exists an [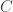 (which may depend on
(which may depend on  ) with
) with 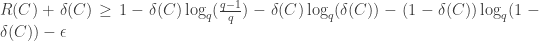 . In particular, in the case
. In particular, in the case  ,
,  , where
, where  is the entropy function (for a q-ary channel).
is the entropy function (for a q-ary channel).
 is known for
is known for 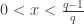 !
!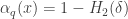 . (In other words, the Gilbert-Varshamov lower bound is actually attained in the case
. (In other words, the Gilbert-Varshamov lower bound is actually attained in the case  . On the other hand, we have the following theorem [J].
. On the other hand, we have the following theorem [J]. is true for infinitely many primes p with
is true for infinitely many primes p with 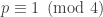 then Goppa’s conjecture is false.
then Goppa’s conjecture is false. means: “For all subsets
means: “For all subsets  ,
,  holds.” The notation
holds.” The notation 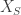 means: For each non-empty subset
means: For each non-empty subset 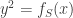 , where
, where  .
. for a particular choice of the parameters. This gives a lower bound for c.
for a particular choice of the parameters. This gives a lower bound for c. and let
and let  is written instead of
is written instead of  , for example).
, for example). to
to  , where
, where . Moreover, the matrix
. Moreover, the matrix  is a generator matrix.
is a generator matrix. is sent over a noisy channel and denote the received word by
is sent over a noisy channel and denote the received word by  . We assume at most 1 error was made.
. We assume at most 1 error was made. in the region of the Venn diagram above associated to coordinate
in the region of the Venn diagram above associated to coordinate 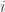 in the table below,
in the table below, 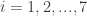 .
.
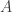 ,
, 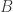 , and
, and 
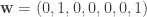 in the binary Hamming code using this algorithm.
in the binary Hamming code using this algorithm. and
and  . Let Player 1 choose the number from the set of integers
. Let Player 1 choose the number from the set of integers 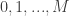 and Player 2 ask the yes/no questions to deduce the number, to which Player 1 is allowed to lie at most e times. Player 2 must discern which number Player 1 picked with a minimum number of questions with no feedback (in other words, all the questions must be provided at once)
and Player 2 ask the yes/no questions to deduce the number, to which Player 1 is allowed to lie at most e times. Player 2 must discern which number Player 1 picked with a minimum number of questions with no feedback (in other words, all the questions must be provided at once)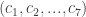 , and each coordinate is placed in the corresponding region of the circle. If Player 1 was completely truthful, then the codeword’s parity conditions hold. This means that the 7-tuple generated by Player 2’s questions will match a 7-tuple from the codeword table above. At this point, Player 2 just has to decode his 7-tuple into an integer using the codeword table above to win the game. A single lie, however, will yield a 7-tuple unlike any in the codeword table. If this is the case, Player 2 must error-check the received codeword using the three parity check bits and the decoding table above. In other words, once Player 2 determines the position of the erroneous bit, he corrects it by “flipping its bit”. Decoding the corrected codeword will yield Player 1’s original number.
, and each coordinate is placed in the corresponding region of the circle. If Player 1 was completely truthful, then the codeword’s parity conditions hold. This means that the 7-tuple generated by Player 2’s questions will match a 7-tuple from the codeword table above. At this point, Player 2 just has to decode his 7-tuple into an integer using the codeword table above to win the game. A single lie, however, will yield a 7-tuple unlike any in the codeword table. If this is the case, Player 2 must error-check the received codeword using the three parity check bits and the decoding table above. In other words, once Player 2 determines the position of the erroneous bit, he corrects it by “flipping its bit”. Decoding the corrected codeword will yield Player 1’s original number.
You must be logged in to post a comment.