What is the best code of a given length? This natural, but very hard, question motivates the following definition.
Definition: Let 
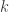

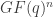
Determining
Let 
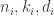


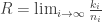


Let 
![(\delta,R)\in [0,1]^2](https://s0.wp.com/latex.php?latex=%28%5Cdelta%2CR%29%5Cin+%5B0%2C1%5D%5E2&bg=ffffff&fg=323232&s=0&c=20201002)


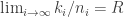
Theorem (Manin [SS]): There exists a continuous decreasing function ![\alpha_q:[0,1]\to [0,1]](https://s0.wp.com/latex.php?latex=%5Calpha_q%3A%5B0%2C1%5D%5Cto+%5B0%2C1%5D&bg=ffffff&fg=323232&s=0&c=20201002)
-
is strictly decreasing on [
],
-
,
- if
then
,
-
.
Theorem (Gilbert-Varshamov): We have 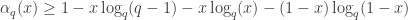
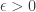
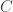

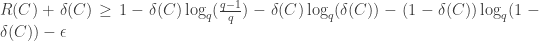



Plot of the Gilbert-Varshamov (dotted), Elias (red), Plotkin (dashed), Singleton (dash-dotted), Hamming (green), and MRRW (stepped) curves using SAGE:

Not a single value of 
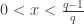
Goppa’s conjecture: 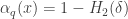
Though my guess is that Goppa’s conjecture is true, it is known (thanks to work of Zink, Vladut and Varshamov) that the q-ary analog of Goppa’s conjecture is false for 
Theorem: If 
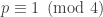
The rest of this post will be devoted to explaining the notation in this Theorem. The notation 


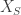
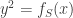

It may seem strange that a statement about the asymptotic bounds of error-correcting curves is related to the number of points on hyperelliptic curves, but for details see [J]. Unfortunately, it appears much more needs to be known about hyperelliptic curves over finite fields if one is to try to use this connection to prove or disprove Goppa’s conjecture.
References:
[J] D. Joyner, On quadratic residue codes and hyperelliptic curves. Discrete Mathematics & Theoretical Computer Science, Vol 10, No 1 (2008).
[SS] S. Shokranian and M.A. Shokrollahi, Coding theory and bilinear complexity, Scientific Series of the International Bureau, KFA Julich Vol. 21, 1994.
Here’s how the above plot is constructed using SAGE:
sage: f1 = lambda x: gv_bound_asymp(x,2)
sage: P1 = plot(f1,0,1/2,linestyle=":")
sage: f2 = lambda x: plotkin_bound_asymp(x,2)
sage: P2 = plot(f2,0,1/2,linestyle="--")
sage: f3 = lambda x: elias_bound_asymp(x,2)
sage: P3 = plot(f3,0,1/2,rgbcolor=(1,0,0))
sage: f4 = lambda x: singleton_bound_asymp(x,2)
sage: P4 = plot(f4,0,1/2,linestyle="-.")
sage: f5 = lambda x: mrrw1_bound_asymp(x,2)
sage: P5 = plot(f5,0,1/2,linestyle="steps")
sage: f6 = lambda x: hamming_bound_asymp(x,2)
sage: P6 = plot(f6,0,1/2,rgbcolor=(0,1,0))
sage: show(P1+P2+P3+P4+P5+P6)
If you are interested in computing what c might be in the above statement B(c,p), the following SAGE code may help.
First, the Python function below will return a random list of elements without repetition, if desired) from an object.
def random_elements(F,n,allow_repetition=True):
"""
F is a SAGE object for which random_element is a method
and having >n elements. For example, a finite field. Here
n>1 is an integer. The output is to have no repetitions
if allow_repetion=False.
EXAMPLES:
sage: p = nth_prime(100)
sage: K = GF(p)
sage: random_elements(K,2,allow_repetition=False)
[336, 186]
The command random_elements(K,p+1,allow_repetition=False)
triggers a ValueError.
"""
if (n>F.order()-2 and allow_repetition==False):
raise ValueError("Parameters are not well-choosen.")
L = []
while len(L)<n:
c = F.random_element()
if allow_repetition==False:
if not(c in L):
L = L+[c]
else:
L = L+[c]
return L
Next, the SAGE code computes 
sage: p = nth_prime(100)
sage: K = GF(p)
sage: R. = PolynomialRing(K, "x")
sage: S = random_elements(K,ZZ((p+1)/2),allow_repetition=False)
sage: fS = prod([x - a for a in S])
sage: XS = HyperellipticCurve(fS)
sage: RR(len(XS.points())/p)
0.975970425138632
Based on experiments with this code, it appears that for “random” chices of S, and p “large”, the quotient
 and let
and let  is written instead of
is written instead of  , for example).
, for example). to
to  , where
, where . Moreover, the matrix
. Moreover, the matrix  is a generator matrix.
is a generator matrix. is sent over a noisy channel and denote the received word by
is sent over a noisy channel and denote the received word by  . We assume at most 1 error was made.
. We assume at most 1 error was made. in the region of the Venn diagram above associated to coordinate
in the region of the Venn diagram above associated to coordinate 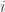 in the table below,
in the table below, 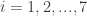 .
.
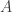 ,
, 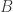 , and
, and 
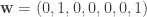 in the binary Hamming code using this algorithm.
in the binary Hamming code using this algorithm. and
and  . Let Player 1 choose the number from the set of integers
. Let Player 1 choose the number from the set of integers 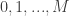 and Player 2 ask the yes/no questions to deduce the number, to which Player 1 is allowed to lie at most e times. Player 2 must discern which number Player 1 picked with a minimum number of questions with no feedback (in other words, all the questions must be provided at once)
and Player 2 ask the yes/no questions to deduce the number, to which Player 1 is allowed to lie at most e times. Player 2 must discern which number Player 1 picked with a minimum number of questions with no feedback (in other words, all the questions must be provided at once)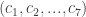 , and each coordinate is placed in the corresponding region of the circle. If Player 1 was completely truthful, then the codeword’s parity conditions hold. This means that the 7-tuple generated by Player 2’s questions will match a 7-tuple from the codeword table above. At this point, Player 2 just has to decode his 7-tuple into an integer using the codeword table above to win the game. A single lie, however, will yield a 7-tuple unlike any in the codeword table. If this is the case, Player 2 must error-check the received codeword using the three parity check bits and the decoding table above. In other words, once Player 2 determines the position of the erroneous bit, he corrects it by “flipping its bit”. Decoding the corrected codeword will yield Player 1’s original number.
, and each coordinate is placed in the corresponding region of the circle. If Player 1 was completely truthful, then the codeword’s parity conditions hold. This means that the 7-tuple generated by Player 2’s questions will match a 7-tuple from the codeword table above. At this point, Player 2 just has to decode his 7-tuple into an integer using the codeword table above to win the game. A single lie, however, will yield a 7-tuple unlike any in the codeword table. If this is the case, Player 2 must error-check the received codeword using the three parity check bits and the decoding table above. In other words, once Player 2 determines the position of the erroneous bit, he corrects it by “flipping its bit”. Decoding the corrected codeword will yield Player 1’s original number. is smallest
is smallest


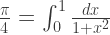
 is biggest
is biggest

You must be logged in to post a comment.