This page is modeled after the handy wikipedia page Table of simple cubic graphs of “small” connected 3-regular graphs, where by small I mean at most 11 vertices.
These graphs are obtained using the SageMath command graphs(n, [4]*n), where n = 5,6,7,… .
5 vertices: Let  denote the vertex set. There is (up to isomorphism) exactly one 4-regular connected graphs on 5 vertices. By Ore’s Theorem, this graph is Hamiltonian. By Euler’s Theorem, it is Eulerian.
denote the vertex set. There is (up to isomorphism) exactly one 4-regular connected graphs on 5 vertices. By Ore’s Theorem, this graph is Hamiltonian. By Euler’s Theorem, it is Eulerian.
4reg5a: The only such 4-regular graph is the complete graph  .
.

We have
- diameter = 1
- girth = 3
- If G denotes the automorphism group then G has cardinality 120 and is generated by (3,4), (2,3), (1,2), (0,1). (In this case, clearly,
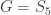 .)
.)
- edge set:

6 vertices: Let 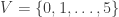 denote the vertex set. There is (up to isomorphism) exactly one 4-regular connected graphs on 6 vertices. By Ore’s Theorem, this graph is Hamiltonian. By Euler’s Theorem, it is Eulerian.
denote the vertex set. There is (up to isomorphism) exactly one 4-regular connected graphs on 6 vertices. By Ore’s Theorem, this graph is Hamiltonian. By Euler’s Theorem, it is Eulerian.
4reg6a: The first (and only) such 4-regular graph is the graph  having edge set:
having edge set:  .
.

We have
- diameter = 2
- girth = 3
- If G denotes the automorphism group then G has cardinality 48 and is generated by (2,4), (1,2)(4,5), (0,1)(3,5).
7 vertices: Let  denote the vertex set. There are (up to isomorphism) exactly 2 4-regular connected graphs on 7 vertices. By Ore’s Theorem, these graphs are Hamiltonian. By Euler’s Theorem, they are Eulerian.
denote the vertex set. There are (up to isomorphism) exactly 2 4-regular connected graphs on 7 vertices. By Ore’s Theorem, these graphs are Hamiltonian. By Euler’s Theorem, they are Eulerian.
4reg7a: The 1st such 4-regular graph is the graph having edge set:  . This is an Eulerian, Hamiltonian (by Ore’s Theorem), vertex transitive (but not edge transitive) graph.
. This is an Eulerian, Hamiltonian (by Ore’s Theorem), vertex transitive (but not edge transitive) graph.

We have
- diameter = 2
- girth = 3
- If G denotes the automorphism group then G has cardinality 14 and is generated by (1,5)(2,4)(3,6), (0,1,3,2,4,6,5).
4reg7b: The 2nd such 4-regular graph is the graph having edge set:  . This is an Eulerian, Hamiltonian graph (by Ore’s Theorem) which is neither vertex transitive nor edge transitive.
. This is an Eulerian, Hamiltonian graph (by Ore’s Theorem) which is neither vertex transitive nor edge transitive.
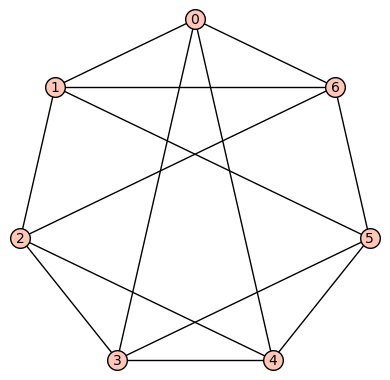
We have
- diameter = 2
- girth = 3
- If G denotes the automorphism group then G has cardinality 48 and is generated by (3,4), (2,5), (1,3)(4,6), (0,2)
8 vertices: Let  denote the vertex set. There are (up to isomorphism) exactly six 4-regular connected graphs on 8 vertices. By Ore’s Theorem, these graphs are Hamiltonian. By Euler’s Theorem, they are Eulerian.
denote the vertex set. There are (up to isomorphism) exactly six 4-regular connected graphs on 8 vertices. By Ore’s Theorem, these graphs are Hamiltonian. By Euler’s Theorem, they are Eulerian.
4reg8a: The 1st such 4-regular graph is the graph having edge set:  . This is vertex transitive but not edge transitive.
. This is vertex transitive but not edge transitive.
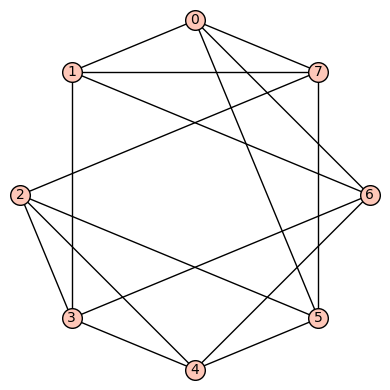
We have
- diameter = 2
- girth = 3
- If G denotes the automorphism group then G has cardinality 16 and is generated by
 and
and  .
.
4reg8b: The 2nd such 4-regular graph is the graph having edge set: . This is a vertex transitive (but not edge transitive) graph.
We have
- diameter = 2
- girth = 3
- If G denotes the automorphism group then G has cardinality 48 and is generated by
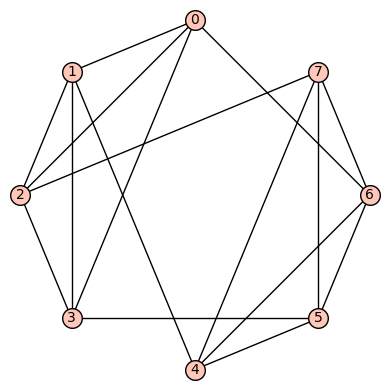
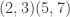 ,
,  ,
,  ,
,  .
.
4reg8c: The 3rd such 4-regular graph is the graph having edge set:  . This is a strongly regular (with “trivial” parameters (8, 4, 0, 4)), vertex transitive, edge transitive graph.
. This is a strongly regular (with “trivial” parameters (8, 4, 0, 4)), vertex transitive, edge transitive graph.
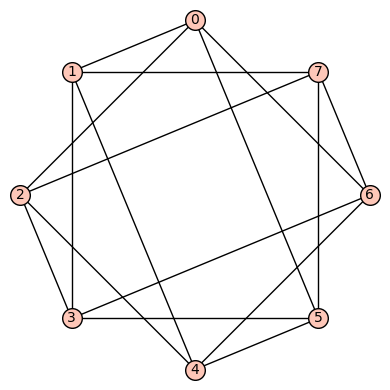
We have
- diameter = 2
- girth = 4
- If G denotes the automorphism group then G has cardinality
 and is generated by (5,6), (4,7), (3,4), (2,5), (1,2), (0,1)(2,3)(4,5)(6,7).
and is generated by (5,6), (4,7), (3,4), (2,5), (1,2), (0,1)(2,3)(4,5)(6,7).
4reg8d: The 4th such 4-regular graph is the graph having edge set:  . This graph is not vertex transitive, nor edge transitive.
. This graph is not vertex transitive, nor edge transitive.

We have
- diameter = 2
- girth = 3
- If G denotes the automorphism group then G has cardinality 16 and is generated by (3,5), (1,4), (0,2)(1,3)(4,5)(6,7), (0,6)(2,7).
4reg8e: The 5th such 4-regular graph is the graph having edge set: 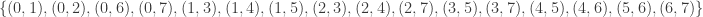 . This graph is not vertex transitive, nor edge transitive.
. This graph is not vertex transitive, nor edge transitive.
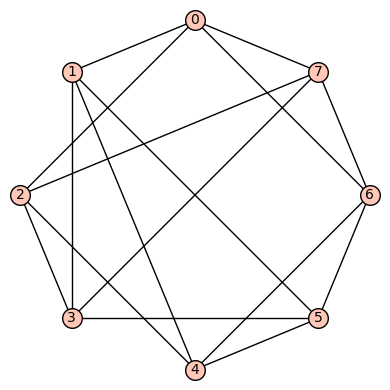
We have
- diameter = 2
- girth = 3
- If G denotes the automorphism group then G has cardinality 4 and is generated by (0,1)(2,4)(3,6)(5,7), (0,2)(1,4)(3,6).
4reg8f: The 6th (and last) such 4-regular graph is the bipartite graph  having edge set:
having edge set: 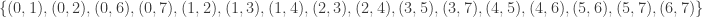 . This graph is not vertex transitive, nor edge transitive.
. This graph is not vertex transitive, nor edge transitive.

We have
- diameter = 2
- girth = 3
- If G denotes the automorphism group then G has cardinality 12 and is generated by (3,4)(6,7), (1,2), (0,3)(5,6).
9 vertices: Let  denote the vertex set. There are (up to isomorphism) exactly 16 4-regular connected graphs on 9 vertices. Perhaps the most interesting of these is the strongly regular graph with parameters (9, 4, 1, 2) (also distance regular, as well as vertex- and edge-transitive). It has an automorphism group of cardinality 72, and is referred to as d4reg9-14 below.
denote the vertex set. There are (up to isomorphism) exactly 16 4-regular connected graphs on 9 vertices. Perhaps the most interesting of these is the strongly regular graph with parameters (9, 4, 1, 2) (also distance regular, as well as vertex- and edge-transitive). It has an automorphism group of cardinality 72, and is referred to as d4reg9-14 below.
Without going into details, it is possible to theoretically prove that there are no harmonic morphisms from any of these graphs to either the cycle graph  or the complete graph
or the complete graph 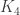 . However, both d4reg9-3 and d4reg9-14 not only have harmonic morphisms to
. However, both d4reg9-3 and d4reg9-14 not only have harmonic morphisms to  , they each may be regarded as a multicover of .
, they each may be regarded as a multicover of .
d4reg9-1
Gamma edges: E1 = [(0, 1), (0, 2), (0, 7), (0, 8), (1, 2), (1, 3), (1, 7), (2, 3), (2, 8), (3, 4), (3, 5), (4, 5), (4, 6), (4, 8), (5, 6), (5, 7), (6, 7), (6, 8)]
diameter: 2
girth: 3
is connected: True
aut gp size: 12
aut gp gens: [(1,2)(4,5)(7,8), (0,1)(3,8)(5,6), (0,4)(1,5)(2,6)(3,7)]

d4reg9-2
Gamma edges: E1 = [(0, 1), (0, 3), (0, 7), (0, 8), (1, 2), (1, 3), (1, 7), (2, 3), (2, 5), (2, 8), (3, 4), (4, 5), (4, 6), (4, 8), (5, 6), (5, 7), (6, 7), (6, 8)]
diameter: 2
girth: 3
is connected: True
aut gp size: 2
aut gp gens: [(0,5)(1,6)(2,8)(3,4)]

d4reg9-3
Gamma edges: E1 = [(0, 1), (0, 2), (0, 7), (0, 8), (1, 2), (1, 3), (1, 4), (2, 3), (2, 8), (3, 4), (3, 5), (4, 5), (4, 6), (5, 6), (5, 7), (6, 7), (6, 8), (7, 8)]
diameter: 2
girth: 3
is connected: True
aut gp size: 18
aut gp gens: [(1,7)(2,8)(3,6)(4,5), (0,1,4,6,8,2,3,5,7)]

d4reg9-4
Gamma edges: E1 = [(0, 1), (0, 5), (0, 7), (0, 8), (1, 2), (1, 4), (1, 7), (2, 3), (2, 4), (2, 5), (3, 4), (3, 6), (3, 8), (4, 5), (5, 6), (6, 7), (6, 8), (7, 8)]
diameter: 2
girth: 3
is connected: True
aut gp size: 4
aut gp gens: [(2,4), (0,6)(1,3)(7,8)]
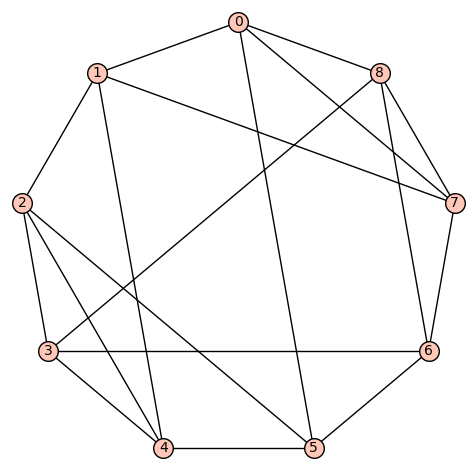
d4reg9-5
Gamma edges: E1 = [(0, 1), (0, 3), (0, 5), (0, 8), (1, 2), (1, 4), (1, 7), (2, 3), (2, 5), (2, 7), (3, 4), (3, 8), (4, 5), (4, 6), (5, 6), (6, 7), (6, 8), (7, 8)]
diameter: 2
girth: 3
is connected: True
aut gp size: 12
aut gp gens: [(1,5)(2,4)(6,7), (0,1)(2,3)(4,5)(7,8)]

d4reg9-6
Gamma edges: E1 = [(0, 1), (0, 3), (0, 7), (0, 8), (1, 2), (1, 5), (1, 6), (2, 3), (2, 5), (2, 6), (3, 4), (3, 8), (4, 5), (4, 7), (4, 8), (5, 6), (6, 7), (7, 8)]
diameter: 2
girth: 3
is connected: True
aut gp size: 8
aut gp gens: [(2,6)(3,7), (0,3)(1,2)(4,7)(5,6)]

d4reg9-7
Gamma edges: E1 = [(0, 1), (0, 3), (0, 4), (0, 8), (1, 2), (1, 3), (1, 6), (2, 3), (2, 5), (2, 7), (3, 4), (4, 5), (4, 8), (5, 6), (5, 7), (6, 7), (6, 8), (7, 8)]
diameter: 2
girth: 3
is connected: True
aut gp size: 2
aut gp gens: [(0,3)(1,4)(2,8)(5,6)]

d4reg9-8
Gamma edges: E1 = [(0, 1), (0, 3), (0, 7), (0, 8), (1, 2), (1, 3), (1, 6), (2, 3), (2, 5), (2, 7), (3, 4), (4, 5), (4, 6), (4, 8), (5, 6), (5, 8), (6, 7), (7, 8)]
diameter: 2
girth: 3
is connected: True
aut gp size: 2
aut gp gens: [(0,8)(1,5)(2,6)(3,4)]
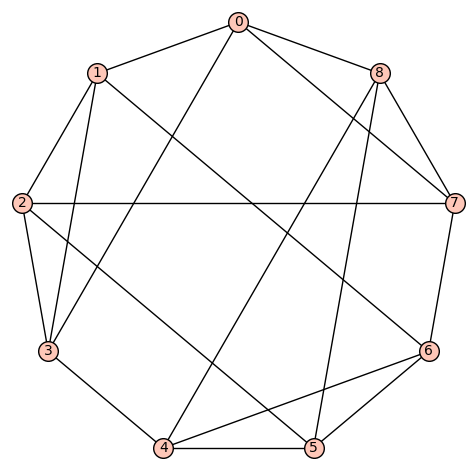
d4reg9-9
Gamma edges: E1 = [(0, 1), (0, 3), (0, 6), (0, 8), (1, 2), (1, 3), (1, 6), (2, 3), (2, 5), (2, 7), (3, 4), (4, 5), (4, 7), (4, 8), (5, 6), (5, 8), (6, 7), (7, 8)]
diameter: 2
girth: 3
is connected: True
aut gp size: 4
aut gp gens: [(5,7), (0,3)(2,6)(4,8)]
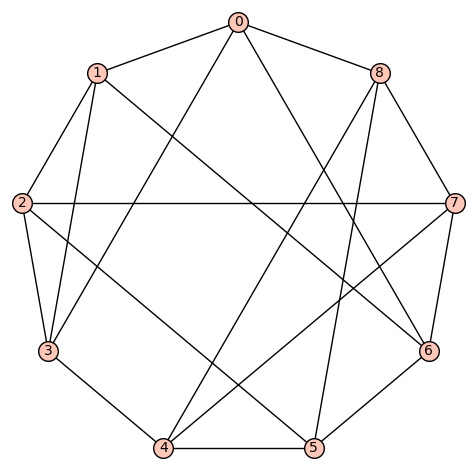
d4reg9-10
Gamma edges: E1 = [(0, 1), (0, 3), (0, 5), (0, 8), (1, 2), (1, 4), (1, 6), (2, 3), (2, 5), (2, 7), (3, 4), (3, 7), (4, 5), (4, 8), (5, 6), (6, 7), (6, 8), (7, 8)]
diameter: 2
girth: 3
is connected: True
aut gp size: 16
aut gp gens: [(2,6)(3,8), (1,5), (0,1)(2,3)(4,5)(6,8)]

d4reg9-11
Gamma edges: E1 = [(0, 1), (0, 3), (0, 7), (0, 8), (1, 2), (1, 4), (1, 6), (2, 3), (2, 5), (2, 7), (3, 4), (3, 5), (4, 5), (4, 8), (5, 6), (6, 7), (6, 8), (7, 8)]
diameter: 2
girth: 3
is connected: True
aut gp size: 8
aut gp gens: [(2,4)(7,8), (0,2)(3,7)(4,6)(5,8)]

d4reg9-12
Gamma edges: E1 = [(0, 1), (0, 3), (0, 6), (0, 8), (1, 2), (1, 4), (1, 6), (2, 3), (2, 5), (2, 7), (3, 4), (3, 7), (4, 5), (4, 8), (5, 6), (5, 8), (6, 7), (7, 8)]
diameter: 2
girth: 3
is connected: True
aut gp size: 18
aut gp gens: [(1,6)(2,5)(3,8)(4,7), (0,1,6)(2,7,3)(4,5,8), (0,2)(1,3)(5,8(6,7)]

d4reg9-13
Gamma edges: E1 = [(0, 1), (0, 3), (0, 4), (0, 8), (1, 2), (1, 5), (1, 6), (2, 3), (2, 5), (2, 7), (3, 4), (3, 7), (4, 5), (4, 8), (5, 6), (6, 7), (6, 8), (7, 8)]
diameter: 2
girth: 3
is connected: True
aut gp size: 8
aut gp gens: [(2,6)(3,8), (0,1)(2,3)(4,5)(6,8), (0,4)(1,5)]
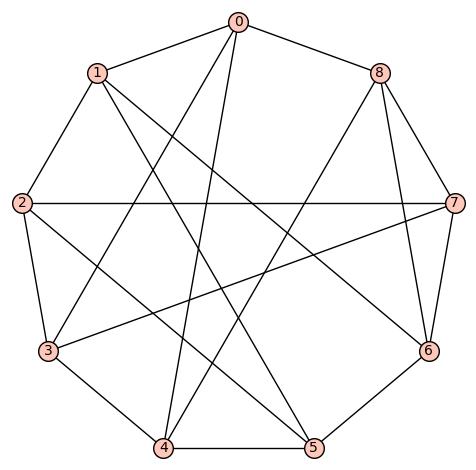
d4reg9-14
Gamma edges: E1 = [(0, 1), (0, 3), (0, 4), (0, 8), (1, 2), (1, 5), (1, 8), (2, 3), (2, 5), (2, 7), (3, 4), (3, 7), (4, 5), (4, 6), (5, 6), (6, 7), (6, 8), (7, 8)]
diameter: 2
girth: 3
is connected: True
aut gp size: 72
aut gp gens: [(2,5)(3,4)(6,7), (1,3)(4,8)(5,7), (0,1)(2,3)(4,5)]

d4reg9-15
Gamma edges: E1 = [(0, 1), (0, 4), (0, 6), (0, 8), (1, 2), (1, 3), (1, 5), (2, 3), (2, 4), (2, 7), (3, 4), (3, 7), (4, 5), (5, 6), (5, 8), (6, 7), (6, 8), (7, 8)]
diameter: 2
girth: 3
is connected: True
aut gp size: 32
aut gp gens: [(6,8), (2,3), (1,4), (0,1)(2,6)(3,8)(4,5)]
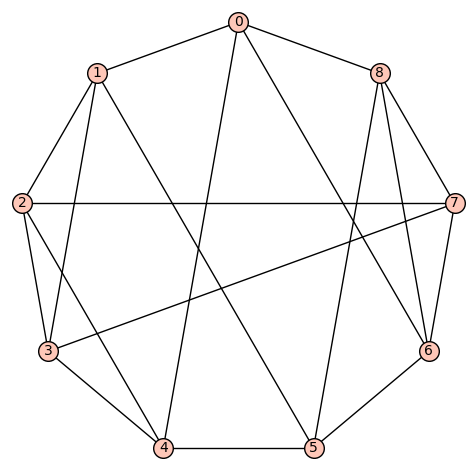
d4reg9-16
Gamma edges: E1 = [(0, 1), (0, 3), (0, 7), (0, 8), (1, 2), (1, 4), (1, 5), (2, 3), (2, 4), (2, 5), (3, 7), (3, 8), (4, 5), (4, 6), (5, 6), (6, 7), (6, 8), (7, 8)]
diameter: 2
girth: 3
is connected: True
aut gp size: 16
aut gp gens: [(7,8), (4,5), (0,1)(2,3)(4,7)(5,8), (0,2)(1,3)(4,7)(5,8)]

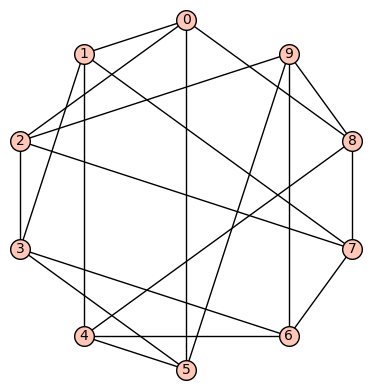
10 vertices: Let  denote the vertex set. There are (up to isomorphism) exactly 59 4-regular connected graphs on 10 vertices. One of these actually has an automorphism group of cardinality 1. According to SageMath: Only three of these are vertex transitive, two (of those 3) are symmetric (i.e., arc transitive), and only one (of those 2) is distance regular.
denote the vertex set. There are (up to isomorphism) exactly 59 4-regular connected graphs on 10 vertices. One of these actually has an automorphism group of cardinality 1. According to SageMath: Only three of these are vertex transitive, two (of those 3) are symmetric (i.e., arc transitive), and only one (of those 2) is distance regular.
Example 1: The quartic, symmetric graph on 10 vertices that is not distance regular is depicted below. It has diameter 2, girth 4, chromatic number 3, and has an automorphism group of order 320 generated by  .
.
Example 2: The quartic, distance regular, symmetric graph on 10 vertices is depicted below. It has diameter 3, girth 4, chromatic number 2, and has an automorphism group of order 240 generated by  .
.

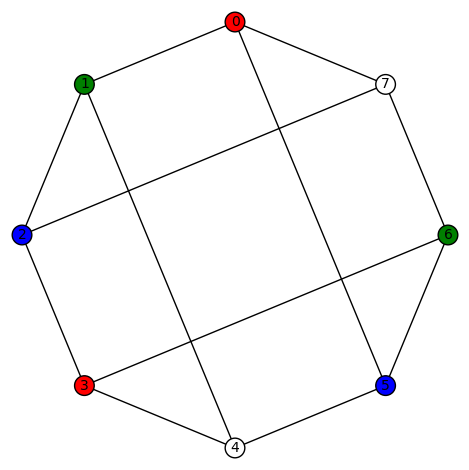
11 vertices: There are (up to isomorphism) exactly 265 4-regular connected graphs on 11 vertices. Only two of these are vertex transitive. None are distance regular or edge transitive.
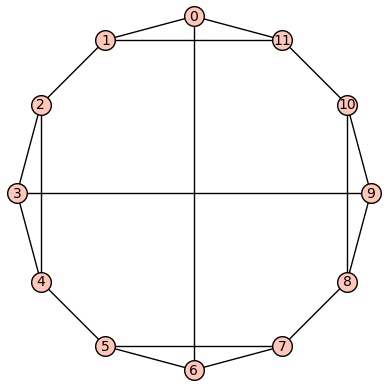
Example 1: One of the vertex transitive graphs is depicted below. It has diameter 2, girth 4, chromatic number 3, and has an automorphism group of order 22 generated by  .
.
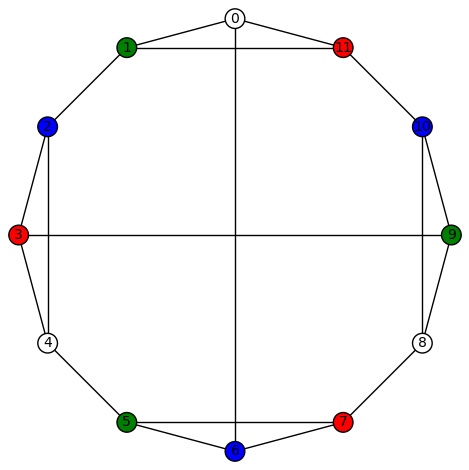
Example 2:The second vertex transitive graph is depicted below. It has diameter 3, girth 3, chromatic number 4, and has an automorphism group of order 22 generated by  .
.



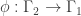 , where
, where 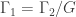 is a quotient graph obtained from some subgroup
is a quotient graph obtained from some subgroup 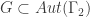 . The examples are for graphs having a small number of vertices (no more than 12). For the most part, we also focused on regular graphs with small degree (no more than 5). They were all computed using
. The examples are for graphs having a small number of vertices (no more than 12). For the most part, we also focused on regular graphs with small degree (no more than 5). They were all computed using 






 (distictly labeled) cards, where
(distictly labeled) cards, where 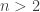 is an integer. The collection of all possible shuffles, or permutations, of this deck is denoted
is an integer. The collection of all possible shuffles, or permutations, of this deck is denoted 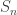 and called the symmetric group. The above discussion leads naturally to the following question(s).
and called the symmetric group. The above discussion leads naturally to the following question(s).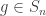 , write that element
, write that element 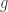 in disjoint cycle notation. Denote the lengths of the disjoint cycles occurring in
in disjoint cycle notation. Denote the lengths of the disjoint cycles occurring in 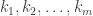 , where
, where 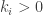 are integers forming a
are integers forming a 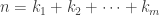 . Then the order of
. Then the order of 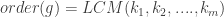 , where LCM denotes the
, where LCM denotes the 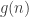 is the function that returns the maximum possible order of an element
is the function that returns the maximum possible order of an element 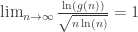 .
. 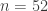 then note
then note 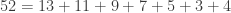 and that
and that 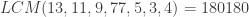 .
.

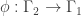 :
:
 – with no vertical multiplicities and all horizontal multiplicities equal to 1. These 24 harmonic morphisms of
– with no vertical multiplicities and all horizontal multiplicities equal to 1. These 24 harmonic morphisms of 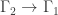 are all coverings and there are no other harmonic morphisms.
are all coverings and there are no other harmonic morphisms. .
.
 .
.




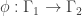 . Call an n1-tuple of “colors”
. Call an n1-tuple of “colors”  a harmonic color list (HCL) if it’s attached to a harmonic morphism in the usual way (the ith coordinate is j if
a harmonic color list (HCL) if it’s attached to a harmonic morphism in the usual way (the ith coordinate is j if  sends vertex i of
sends vertex i of  of
of 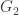 of
of  orbits. The conjecture is that there is only one such orbit.
orbits. The conjecture is that there is only one such orbit. 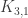 ), C4 (the cycle graph), K4 (the complete graph), Paw (C3 with a “tail”), and Diamond (K4 but missing an edge). All these terms are used on
), C4 (the cycle graph), K4 (the complete graph), Paw (C3 with a “tail”), and Diamond (K4 but missing an edge). All these terms are used on  . This graph is not vertex transitive. Its characteristic polynomial is
. This graph is not vertex transitive. Its characteristic polynomial is 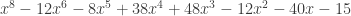 . Its edge connectivity and vertex connectivity are both 2. This graph has no non-trivial harmonic morphisms to D3 or P4 or C4 or Paw. However, there are 48 non-trivial harmonic morphisms to
. Its edge connectivity and vertex connectivity are both 2. This graph has no non-trivial harmonic morphisms to D3 or P4 or C4 or Paw. However, there are 48 non-trivial harmonic morphisms to  . For example,
. For example, 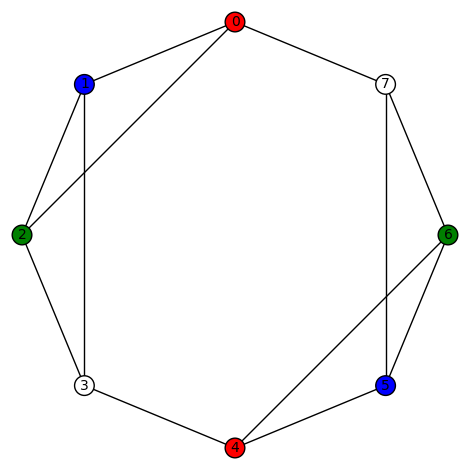 (the automorphism group of K4, ie the symmetric group of degree 4, acts on the colors {0,1,2,3} and produces 24 total plots), and
(the automorphism group of K4, ie the symmetric group of degree 4, acts on the colors {0,1,2,3} and produces 24 total plots), and  (again, the automorphism group of K4, ie the symmetric group of degree 4, acts on the colors {0,1,2,3} and produces 24 total plots). There are 8 non-trivial harmonic morphisms to
(again, the automorphism group of K4, ie the symmetric group of degree 4, acts on the colors {0,1,2,3} and produces 24 total plots). There are 8 non-trivial harmonic morphisms to  . For example,
. For example,  and
and  Here the automorphism group of K4, ie the symmetric group of degree 4, acts on the colors {0,1,2,3}, while the automorphism group of the graph
Here the automorphism group of K4, ie the symmetric group of degree 4, acts on the colors {0,1,2,3}, while the automorphism group of the graph  (obviously too small to act transitively on the vertices). Its characteristic polynomial is
(obviously too small to act transitively on the vertices). Its characteristic polynomial is  , its edge connectivity and vertex connectivity are both 3. This graph has no non-trivial harmonic morphisms to D3 or P4 or C4 or Paw or K4. However, it has 4 non-trivial harmonic morphisms to Diamond. They are:
, its edge connectivity and vertex connectivity are both 3. This graph has no non-trivial harmonic morphisms to D3 or P4 or C4 or Paw or K4. However, it has 4 non-trivial harmonic morphisms to Diamond. They are:

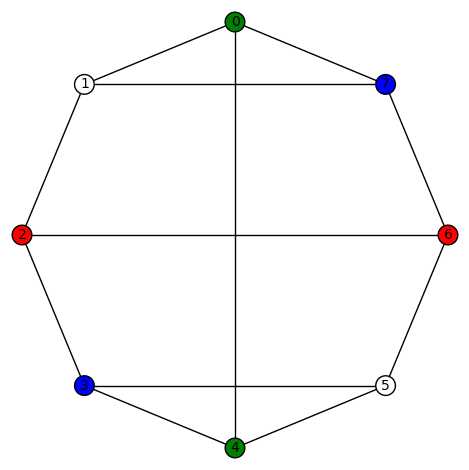 Let
Let  . It does not act transitively on the vertices. Its characteristic polynomial is
. It does not act transitively on the vertices. Its characteristic polynomial is  and its edge connectivity and vertex connectivity are both 3.
and its edge connectivity and vertex connectivity are both 3. 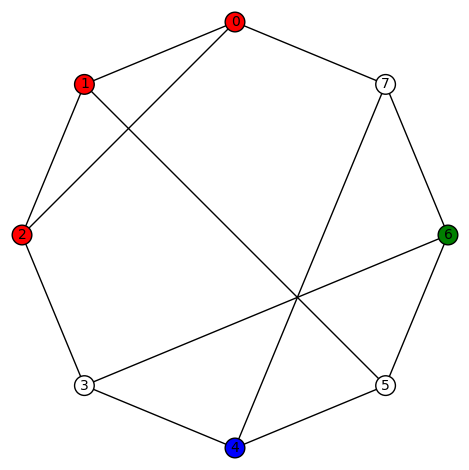
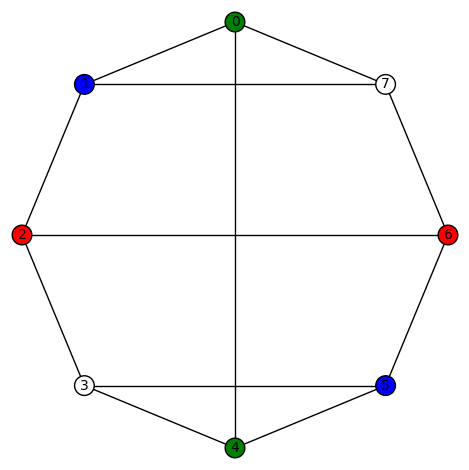
 , this graph
, this graph  . It is vertex transitive. Its characteristic polynomial is
. It is vertex transitive. Its characteristic polynomial is  and its edge connectivity and vertex connectivity are both 3.
and its edge connectivity and vertex connectivity are both 3.  A few examples of a non-trivial harmonic morphism to Diamond:
A few examples of a non-trivial harmonic morphism to Diamond: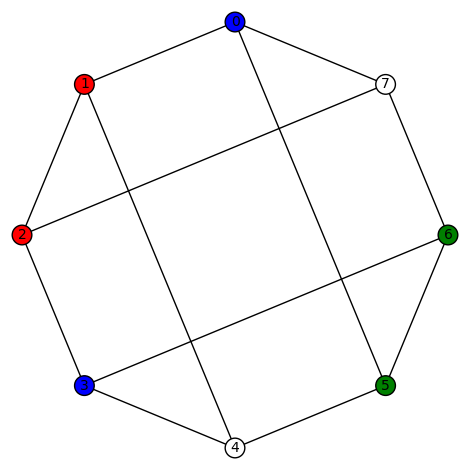 and
and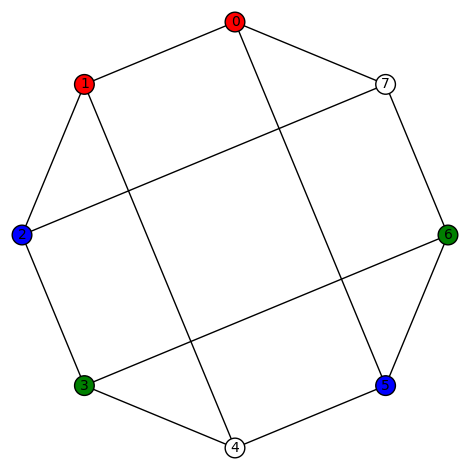 A few examples of a non-trivial harmonic morphism to C4:
A few examples of a non-trivial harmonic morphism to C4:



You must be logged in to post a comment.