In Stanislaw Ulam’s 1976 autobiography (Adventures of a mathematician, Scribner and Sons, New York, 1976), one finds the following problem concerning two players playing a generalization of the childhood game of “20 questions”.
(As a footnote: the history of who invented this game is unclear. It occurred in writings of Renyi, for example “On a problem in information theory” (Hungarian), Magyar Tud. Akad. Mat. Kutató Int. Közl. 6 (1961)505–516, but may have been known earlier under the name “Bar-kochba”.)
Problem: Player 1 secretly chooses a number from 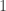
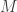
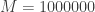


There is a very large literature on this problem. Just google “searching with lies” (with the quotes) to see a selection of the papers (eg, this paper). It turns out this children’s game, when suitably generalized, has numerous applications to computer science and engineering.
We start with a simple example. Pick an integer from 0 to 1000000. For example, suppose you pick 

Here is how I can ask you 20 True/False questions and guess your number.
Is your number less than 524288? False

Is your number less than 655360? True
Is your number less than 589824? True

Is your number less than 557056? True
Is your number less than 540672? True
Is your number less than 532480? True
Is your number less than 528384? True
Is your number less than 526336? True
Is your number less than 525312? True
Is your number less than 524800? True
Is your number less than 524544? True
Is your number less than 524416? True
Is your number less than 524352? True
Is your number less than 524320? True
Is your number less than 524304? True
Is your number less than 524296? True
Is your number less than 524292? True
Is your number less than 524290? True
Is your number less than 524289? False
This is the general description of the binary search strategy:
First, divide the whole interval of size 
Second, divide the subinterval of size 
Third, divide the subinterval of size 
And so on.
This process must stop after 20 steps, as you run out of non-trivial subintervals.
This is an instance of “searching with lies” where no lies are told and “feedback” is allowed.
Another method:
I don’t know what your number is, but whatever it is, represent it in binary as a vector

where 

Is 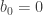
Is 
and so on
Is 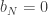
You may determine the value of the 

This is an instance of “searching with lies” where no lies are told and “feedback” is not allowed.
Let’s go back to our problem where Player 1 secretly chooses a number from 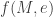

Clearly,

In practice, we not only want to know 
In his 1964 PhD thesis (E. Berlekamp, Block coding with noiseless feedback, PhD Thesis, Dept EE, MIT, 1964), Berlekamp was concerned with a discrete analog of a problem which arises when trying to design a analog-to-digital converter for sound recording which compensates for possible feedback.
To formulate this problem in the case when lies are possible, we introduce some new terms.
Definitions
A binary code is a set 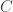




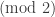

The Hamming distance between 


The minimum distance of 


For example, let

This is a 1-error correcting code of minimum distance 
We say that 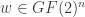
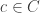

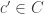
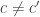
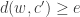
Let 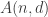
Fact: If a binary code 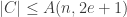
Let 
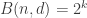
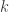
Clearly, 
A Reduction
Fact: Fix any 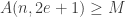
Record the 

We want the smallest possible 


Here’s a recipe for using online tables to find a good upper bound the smallest number Q of questions Player 2 must ask Player 1, if Player 1 gets to lie
-
Find the smallest k such that
,
-
go to the table minT and go to the row
- that column number n is an upper bound for Q.
 be
be  , and let
, and let  be different from the zero element of
be different from the zero element of 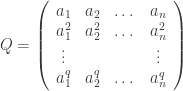

 and
and 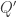 , will presently be illustrated. We note here merely that each of the matrices
, will presently be illustrated. We note here merely that each of the matrices 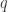 . Let us examine
. Let us examine 
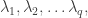

 ). The
). The 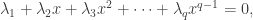
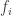 and the
and the 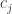
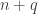 elements of a telegraphic sequence
elements of a telegraphic sequence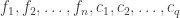

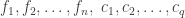

 errors which affect the
errors which affect the 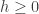 errors which affect the
errors which affect the 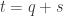 . Then, to avoid discussing again the case already considered, we assume that at least one of the two integers
. Then, to avoid discussing again the case already considered, we assume that at least one of the two integers 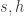
 , affecting the
, affecting the 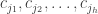 . Without loss in generality, we may assume that the
. Without loss in generality, we may assume that the  errors affecting the
errors affecting the  , so that the first
, so that the first 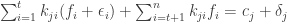
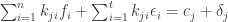

 and where
and where  in
in 
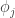 denotes a polynomial in the errors
denotes a polynomial in the errors  .
.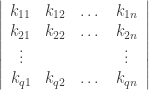

 , be equal to zero, contrary to hypothesis.
, be equal to zero, contrary to hypothesis. is different from
is different from  are uniquely determined as functions of the
are uniquely determined as functions of the  :
:
 being, of course, rational functions. But, by assumption, all of the $\delta_j$, except
being, of course, rational functions. But, by assumption, all of the $\delta_j$, except  , vanish. Hence
, vanish. Hence  ) is a rational function of
) is a rational function of  .
. errors, is to check up, so that the presence of error can escape detection,
errors, is to check up, so that the presence of error can escape detection,  errors.
errors. denote the total number of elements in the finite algebraic field
denote the total number of elements in the finite algebraic field  values — an error with the value
values — an error with the value 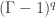 of being accidentally adjusted so as to escape detection.
of being accidentally adjusted so as to escape detection. errors occur among the
errors occur among the  , the errors being all of accidental telegraphic origin, the presence of error will infallibly be disclosed if
, the errors being all of accidental telegraphic origin, the presence of error will infallibly be disclosed if  ; and will enjoy a
; and will enjoy a  is greater than
is greater than 
 ,
, 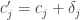 , where
, where 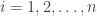 ,
,  , the errors
, the errors  (resp.,
(resp., 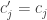 ).
).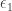 ,
,  . Since the
. Since the 
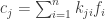 . Hence the message will fail to check, and the presence of error will be disclosed, unless the
. Hence the message will fail to check, and the presence of error will be disclosed, unless the 
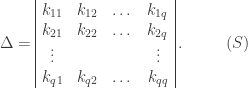
 , for
, for 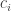 , and not more than
, and not more than 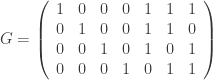 and check matrix
and check matrix 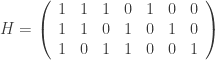 . In other words, this code is the row space of G and the kernel of H. We can enter these into Sage as follows:
. In other words, this code is the row space of G and the kernel of H. We can enter these into Sage as follows: defined by
defined by 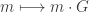 . Using this map, the codewords are easy to describe and enumerate:
. Using this map, the codewords are easy to describe and enumerate: .
.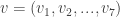 . This must be a codeword (no lies) or differ from a codeword by exactly one bit (1 lie). In either case, you can find n by decoding this vector.
. This must be a codeword (no lies) or differ from a codeword by exactly one bit (1 lie). In either case, you can find n by decoding this vector.
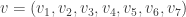 .
.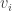 in region i of the Venn diagram.
in region i of the Venn diagram.






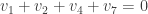
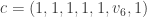 , for some unknown
, for some unknown  . We solve for this unknown using the check vertex equation
. We solve for this unknown using the check vertex equation  . The decoded codeword is
. The decoded codeword is 
 . In this case, we know the vertices 9 and 10 fail, so
. In this case, we know the vertices 9 and 10 fail, so  . We solve using
. We solve using 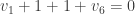

 . By majority vote, we get
. By majority vote, we get  .
. 
 is the number of blocks that contain any i-element set of points.
is the number of blocks that contain any i-element set of points. , where
, where 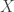 is a non-empty finite set of
is a non-empty finite set of 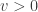 elements called points, and
elements called points, and 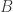 is a non-empty finite multiset of size
is a non-empty finite multiset of size  whose elements are called blocks, such that each block is a non-empty finite multiset of
whose elements are called blocks, such that each block is a non-empty finite multiset of 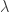 blocks the the block design is called a
blocks the the block design is called a  design (or simply a
design (or simply a  then the block design is called a
then the block design is called a  Steiner system.
Steiner system. ] code and let
] code and let  denote the weight
denote the weight 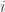 subset of codewords of weight
subset of codewords of weight  denote the support of the codeword.
denote the support of the codeword. ]-code
]-code 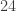 . This is a self-dual [
. This is a self-dual [ is a
is a  design;
design; 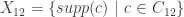 is a
is a 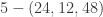 design;and,
design;and,  is a
is a  design.
design.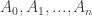 be the weight distribution of the codewords in a binary linear [
be the weight distribution of the codewords in a binary linear [ ] code
] code  be the weight distribution of the codewords in its dual [
be the weight distribution of the codewords in its dual [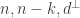 ] code
] code 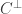 . Fix a
. Fix a  , and let
, and let  .
. .
.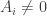 and
and  then
then 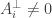 and
and  then
then  holds a simple
holds a simple  of coordinate locations and
of coordinate locations and  is the set of supports of the codewords of
is the set of supports of the codewords of  are
are ,
, , (this k is not to be confused with dim(C)!),
, (this k is not to be confused with dim(C)!), ,
,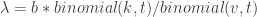
 . Moreover, the code is spanned by the codewords of weight 8.
. Moreover, the code is spanned by the codewords of weight 8.
You must be logged in to post a comment.