It’s easy to imagine the 19th century Philadelphia wool dealer Frank J. Primrose as a happy man. I envision him shearing sheep during the day, while in the evening he brings his wife flowers and plays games with his little children until bedtime. However, in 1887 Frank J. Primrose was not a happy man. This is because in June of that year, he had telegraphed his agent in Kansas instructions to buy a certain amount of wool. However, the telegraph operator made a single mistake in transmitting his message and Primrose unintentionally bought far more wool than he could possibly sell. Ordinarily, such a small error has little consequence, because errors can often be detected from the context of the message. However, this was an unusual case and the mistake cost him about a half-million dollars in today’s money. He promptly sued and his case eventually made its way to the Supreme Court. The famous 1894 United States Supreme Court case Primrose v. Western Union Telegraph Company decided that the telegraph company was not liable for the error in transmission of a message.
Thus was born the need for error-correcting codes.
Introduction
Lester Hill is most famously known for the Hill cipher, frequently taught in linear algebra courses today. We describe this cryptosystem in more detail in one of the sections below, but here is the rough idea. In this system, developed and published in the 1920’s, we take a 

On the other hand, Richard Hamming is known for the Hamming codes, also frequently taught in a linear algebra course. This will be describes in more detail in one of the sections below, be here is the basic idea. In this scheme, developed in the 1940’s, we take a 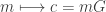
Here, in a nutshell, is the mystery at the heart of this post.
These schemes of Hill and Hamming, while algebraically very similar, have quite different aims. One is intended for secure communication, the other for reliable communication. However, in an unpublished paper [H5], Hill developed a hybrid encryption/error-detection scheme, what we shall call “Hill codes” (described in more detail below).
Why wasn’t Hill’s result published and therefore Hill, more than Hamming, known as a pioneer of error-correcting codes?
Perhaps Hill himself hinted at the answer. In an overly optimistic statement, Hill wrote (italics mine):
Further problems connected with checking operations in finite fields will be treated in another paper. Machines may be devised to render almost quite automatic the evaluation of checking elements
according to any proposed reference matrix of the general type described in Section 7, whatever the finite field in which the operations are effected. Such machines would enable us to dispense entirely with tables of any sort, and checks could be determined with great speed. But before checking machines could be seriously planned, the following problem — which is one, incidentally, of considerable interest from the standpoint of pure number theory — would require solution.
– Lester Hill, [H5]
By my interpretation, this suggests Hill wanted to answer the question below before moving on. As simple looking as it is, this problem is still, as far as I know, unsolved at the time of this writing.
Question 1 (Hill’s Problem):
Given k and q, find the largest r such that there exists a 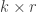
Indeed, this is closely related to the following related question from MacWilliams-Sloane [MS77], also still unsolved at this time. (Since Cauchy matrices do give a large family of matrices with the desired property, I’m guessing Hill was not aware of them.)
Question 2: Research Problem (11.1d)
Given k and q, find the largest r such that there exists a
In this post, after brief biographies, an even more brief description of the Hill cipher and Hamming codes is given, with examples. Finally, we reference previous blog posts where the above-mentioned unpublished paper, in which Hill discovered error-correcting codes, is discussed in more detail.
Short biographies
Who is Hill? Recent short biographies have been published by C. Christensen and his co-authors. Modified slightly from [C14] and [CJT12] is the following information.
Lester Sanders Hill was born on January 19, 1890 in New York. He graduated from Columbia University in 1911 with a B. A. in Mathematics and earned his Master’s Degree in 1913. He taught mathematics for a few years at Montana University, then at Princeton University. He served in the United States Navy Reserves during World War I. After the WWI, he taught at the University of Maine and then at Yale, from which he earned his Ph.D. in mathematics in 1926. His Ph.D. advisor is not definitely known at this writing but I think a reasonable guess is Wallace Alvin Wilson.
In 1927, he accepted a position with the faculty of Hunter College in New York City, and he remained there, with one exception, until his resignation in 1960 due to illness. The one exception was for teaching at the G.I. University in Biarritz in 1946, during which time he may have been reactivated as a Naval Reserves officer. Hill died January 9, 1961.
Thanks to an interview that David Kahn had with Hill’s widow reported in [C14], we know that Hill loved to read detective stories, to tell jokes and, while not shy, enjoyed small gatherings as opposed to large parties.
Who is Hamming? His life is much better known and details can be readily found in several sources.
Richard Wesley Hamming was born on February 11, 1915, in Chicago. Hamming earned a B.S. in mathematics from the University of Chicago in 1937, a masters from the University of Nebraska in 1939, and a PhD in mathematics (with a thesis on differential equations)
from the University of Illinois at Urbana-Champaign in 1942. In April 1945 he joined the Manhattan Project at the Los Alamos Laboratory, then left to join the Bell Telephone Laboratories in 1946. In 1976, he retired from Bell Labs and moved to the Naval Postgraduate School in Monterey, California, where he worked as an Adjunct Professor
and senior lecturer in computer science until his death on January 7, 1998.
Hill’s cipher
The Hill cipher is a polygraphic cipher invented by Lester S. Hill in 1920’s. Hill and his colleague Wisner from Hunter College filed a patent for a telegraphic device encryption and error-detection device which was roughly based on ideas arising from the Hill cipher. It appears nothing concrete became of their efforts to market the device to the military, banks or the telegraph company (see Christensen, Joyner and Torres [CJT12] for more details). Incidently, Standage’s excellent book [St98] tells the amusing story of the telegraph company’s failed attempt to add a relatively simplistic error-detection to telegraph codes during that time period.
Some books state that the Hill cipher never saw any practical use in the real world. However, research by historians F. L. Bauer and David Kahn uncovered the fact that the Hill cipher saw some use during World War II encrypting three-letter groups of radio call signs [C14]. Perhaps insignificant, at least compared to the practical value of Hamming codes, none-the-less, it was a real-world use.
The following discussion assumes an elementary knowledge of matrices. First, each letter is first encoded as a number, namely
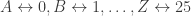


The construction
Suppose your message m consists of n capital letters, with no spaces. This may be regarded an n-tuple M with elements in R = Z/26Z. Identify the message M as a sequence of column vectors 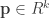
The encryption is performed by computing 

Example 1: Suppose m is the message “BWGN”. Transcoding into numbers, the plaintext is rewritten 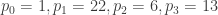
Using Hill’s encryption above gives 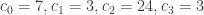
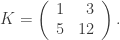
Security concerns: For example, this cipher is linear and can be broken by a known plaintext attack.
Hamming codes
Richard Hamming is a pioneer of coding theory, introducing the binary
Hamming codes in the late 1940’s. In the days when an computer error could crash the computer and force the programmer to retype his punch cards, Hamming, out of frustration, designed a system whereby the computer could automatically correct certain errors. The family of codes named after him can easily correct one error.
Hill’s unpublished paper
While he was a student at Yale, Hill published three papers in Telegraph and Telephone Age [H1], [H2], [H3]. In these papers Hill described a mathematical method for checking the accuracy of telegraph communications. There is some overlap with these papers and [H5], so it seems likely to me that Hill’s unpublished paper [H5] dates from this time (that is, during his later years at Yale or early years at Hunter).
In [H5], Hill describes a family of linear block codes over a finite field and an algorithm for error-detection (which can be easily extended to error-correction). In it, he states the construction of what I’ll call the “Hill codes,” (defined below), gives numerous computational examples, and concludes by recording Hill’s Problem (stated above as Question 1). It is quite possibly Hill’s best work.
Here is how Hill describes his set-up.
Our problem is to provide convenient and practical accuracy checks upon
a sequence of n elementsin a finite algebraic
field F. We send, in place of the simple sequence
consisting of the “operand” sequence and the “checking” sequence.

– Lester Hill, [H5]
Then Hill continues as follows. Let F=GF(p) denote the finite field having p elements, where 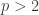
for 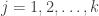
fixed matrix
of elements of F, the matrix having been constructed according to the criteria in Hill’s Problem above. In other words, if the operand sequence (i.e., the message) is the vector 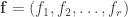

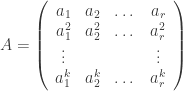
where 

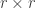
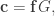
We conclude with one more open question.
Question 3:
What is the minimum distance of a Hill code?
The minimum distance of any Hamming code is 3.
Do all sufficiently long Hill codes have minimum distance greater than 3?
Summary
Most books today (for example, the excellent MAA publication written by Thompson [T83]) date the origins of the theory of error-correcting codes to the late 1940s, due to Richard Hamming. However, this paper argues that the actual birth is in the 1920s due to Lester Hill. Topics discussed include why Hill’s discoveries weren’t publicly known until relatively recently, what Hill actually did that trumps Hamming, and some open (mathematical) questions connected with Hill’s work.
For more details, see these previous blog posts.
Acknowledgements: Many thanks to Chris Christensen and Alexander Barg for
helpful and encouraging conversations. I’d like to explicitly credit Chris Christensen, as well as historian David Kahn, for the original discoveries of the source material.
Bibliography
[C14] C. Christensen, Lester Hill revisited, Cryptologia 38(2014)293-332.
[CJT12] ——, D. Joyner and J. Torres, Lester Hill’s error-detecting codes, Cryptologia 36(2012)88-103.
[H1] L. Hill, A novel checking method for telegraphic sequences, Telegraph and
Telephone Age (October 1, 1926), 456 – 460.
[H2] ——, The role of prime numbers in the checking of telegraphic communications, I, Telegraph and Telephone Age (April 1, 1927), 151 – 154.
[H3] ——, The role of prime numbers in the checking of telegraphic
communications, II, Telegraph and Telephone Age (July, 16, 1927), 323 – 324.
[H4] ——, Lester S. Hill to Lloyd B. Wilson, November 21, 1925. Letter.
[H5] ——, Checking the accuracy of transmittal of telegraphic communications by means of operations in finite algebraic fields, undated and unpublished notes, 40 pages.
(hill-error-checking-notes-unpublished)
[MS77] F. MacWilliams and N. Sloane, The Theory of Error-Correcting Codes, North-Holland, 1977.
[Sh] A. Shokrollahi, On cyclic MDS codes, in Coding Theory and Cryptography: From Enigma and Geheimschreiber to Quantum Theory, (ed. D. Joyner), Springer-Verlag, 2000.
[St98] T. Standage, The Victorian Internet, Walker & Company, 1998.
[T83] T. Thompson, From Error-Correcting Codes Through Sphere Packings to Simple Groups, Mathematical Association of America, 1983.
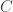 be the binary Hamming [7,4,3] code defined by the generator matrix
be the binary Hamming [7,4,3] code defined by the generator matrix 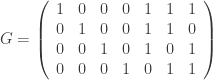 and check matrix
and check matrix 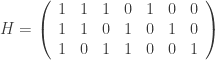 . In other words, this code is the row space of G and the kernel of H. We can enter these into Sage as follows:
. In other words, this code is the row space of G and the kernel of H. We can enter these into Sage as follows: defined by
defined by 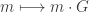 . Using this map, the codewords are easy to describe and enumerate:
. Using this map, the codewords are easy to describe and enumerate: .
.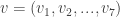 . This must be a codeword (no lies) or differ from a codeword by exactly one bit (1 lie). In either case, you can find n by decoding this vector.
. This must be a codeword (no lies) or differ from a codeword by exactly one bit (1 lie). In either case, you can find n by decoding this vector.
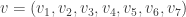 .
. in region i of the Venn diagram.
in region i of the Venn diagram.






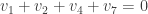
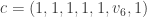 , for some unknown
, for some unknown  . We solve for this unknown using the check vertex equation
. We solve for this unknown using the check vertex equation  . The decoded codeword is
. The decoded codeword is 
 . In this case, we know the vertices 9 and 10 fail, so
. In this case, we know the vertices 9 and 10 fail, so  . We solve using
. We solve using 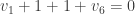

 . By majority vote, we get
. By majority vote, we get  .
.  is its length,
is its length,  is its dimension, and
is its dimension, and 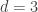 is its minimum distance),
is its minimum distance), 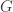 is a generating matrix,
is a generating matrix,  is a check matrix, and
is a check matrix, and 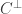 is the dual code of
is the dual code of 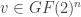 to be a cover, and the message
to be a cover, and the message  we embed is an element of
we embed is an element of  . Once we find a vector
. Once we find a vector  of lowest weight such that
of lowest weight such that 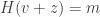 , we call
, we call  the stegocover. The stegocover looks a lot like the original cover and “contains” the message m. This will be explained in more detai below.
the stegocover. The stegocover looks a lot like the original cover and “contains” the message m. This will be explained in more detai below. .
. with a fixed basis, where
with a fixed basis, where  is an integer called the length of the code. Moreover, the basis for the ambient space
is an integer called the length of the code. Moreover, the basis for the ambient space 
 are the rows of
are the rows of 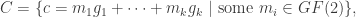
 . The vector of coefficients,
. The vector of coefficients,  represents the information you want to encode and transmit.
represents the information you want to encode and transmit.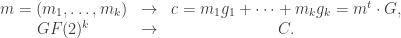
 . This matrix is called a check matrix of
. This matrix is called a check matrix of 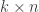 matrix then a full rank check matrix
matrix then a full rank check matrix 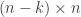 matrix.
matrix.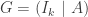 is the generating matrix for
is the generating matrix for  is a parity check matrix.
is a parity check matrix. be an integer and let
be an integer and let  matrix whose columns are all the distinct non-zero vectors of
matrix whose columns are all the distinct non-zero vectors of  , and let
, and let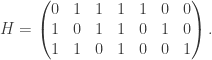
 , the generator matrix
, the generator matrix 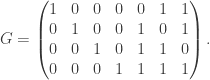
 is a subset of
is a subset of  for some
for some  . Let
. Let 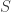 be a coset of
be a coset of  .
.
 is a set of all possible covers
is a set of all possible covers
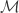 is a set of all possible messages
is a set of all possible messages
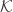 is a set of all possible keys
is a set of all possible keys
 is an embedding function
is an embedding function
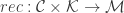 is a recovery function
is a recovery function

 ,
,  ,
,  . We will assume that a fixed key
. We will assume that a fixed key  is called the plain cover,
is called the plain cover,  is called the stegocover. Let
is called the stegocover. Let  , where
, where 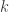 is a fixed integer such that
is a fixed integer such that 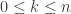 .
.  and consider the cover
and consider the cover  . Regarded as a
. Regarded as a  matrix,
matrix, 
 . First we compute the stegocover:
. First we compute the stegocover:

You must be logged in to post a comment.