Yes, I more-or-less stole the above title from the 2004 Ken Ross book entitled A Mathematician at the Ballpark. Like that book, anyone familiar with middle-school (or junior high school) math, should have no problem with most of what we do here. However, I will try to go into baseball in more detail than the book did.
Paraphrasing slightly, I read somewhere the following facetious remark:
From a survey of 1000 random baseball fans
across the nation, 183% of them hate math.
If you are one of these 183%, then this series could be for you. Hopefully, even if you aren’t a baseball expert, but you would like to learn some baseball statistics, (now often called “sabermetrics”), these posts will help. I’m no expert myself, so we’ll learn together.
In this series of blog posts, each post will introduce a particular metric in baseball statistics as well as some of the math and baseball behind it. We illustrate all these notions using the Baltimore Orioles’ 2022 season.
This week we look at one of the most popular statistics you see on televised games: OPS or “On-base Plus Slugging,” which is short for on-base percentage plus slugging percentage. Don’t worry, we’ll explain all these terms as we go.
On-base percentage
First, On-Base Percentage or OBP is a more recent version of On-Base Average or OBA (the same as OBP but the SF term is omitted). We define
OBP = (H + BB + HBP)/(AB + BB + HBP + SF),
where
- H is the number of Hits (the times the batter reaches base because of a batted, fair ball without error by the defense),
- BB is the number of Base-on-Balls (or walks), where a batter receives four pitches that the umpire calls balls, and is in turn awarded first base,
- HBP, or Hit By Pitch, counts the times this hitter is touched by a pitch and awarded first base as a result, and
- SF is the number of Sacrifice Flies and AB the number of At-Bats, which are more complicated to carefully define.
The official scorer keeps track of all these numbers, and more, as the baseball game is played. We still have to define the expressions AB and SF.
First, SF, or Sacrifice Flies, counts the number of fly balls hit to the outfield for which both of the following are true:
- this fly is caught for an out, and a baserunner scores after the catch (so there must be at most one hit at the time),
- the fly is dropped, and a runner scores, if in the scorer’s judgment the runner could have scored after the catch had the fly ball been caught.
A sacrifice fly is only credited if a runner scores on the play. (By the way, this is a “recent” statistic, as they weren’t tabulated before 1954. Between 1876, when the major league baseball national league was born, and 1954 baseball analysts used the OBA instead.)
Second, AB, or At-Bats, counts those plate appearances that are not one of the following:
- A walk,
- being hit by a pitch,
- a bunt (or Sacrifice Hit, SH),
- a sacrifice fly,
- interference (the catcher hitting the bat with his glove, for example), or
- an obstruction (by the first baseman blocking the base path, for example).
Incidentally, the self-explanatory number Plate Appearances, or PA, can differ from AB by as much as 10%, mostly due to the number of walks that a batter can draw.
The main terms in the OBP expression are H and AB. So we naturally expect OBP to be approximately equal to the Batting Average, defined by
BA = H/AB,
For example, if we take the top 18 Orioles players and plot the BA vs the OBP, we get the following graph:
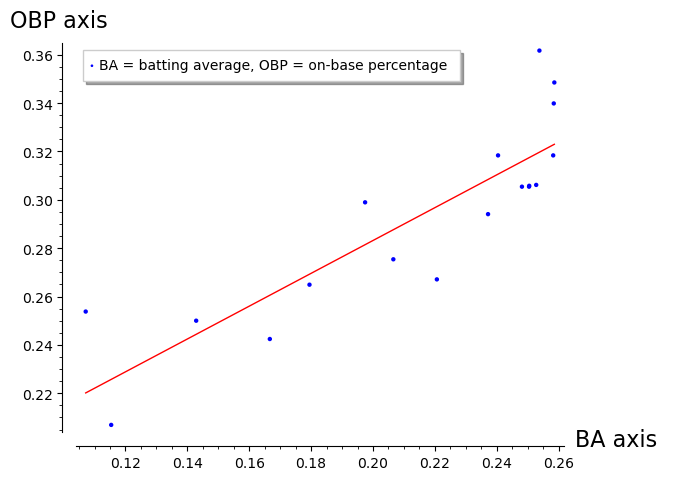
The line shown above is simply the line of best fit to visually indicate the correlation.
Example: As an example, let’s look at the Orioles’ All-Star center fielder, Curtis Mullins, who had 672 plate appearances and 608 at bats, for a difference of 672 − 608 = 64. He had 1 bunt, 5 sacrifice flies, he was hit by a pitch 9 times, and walked 47 times. These add up to 62, so (using the above definition of AB) the number of times he was awarded 1st base due to interference or obstruction was 64 − 62 = 2.
Mullins’ H = 157 hits break down into 105 singles, 32 doubles, 4 triples, and 16 home runs.
Second, let’s add to these his 126 strikeouts, for a total of 157+126+64 = 347.
The remaining 608 − 347 = 261 plate appearances were pitches hit by Mullins, but either caught on the fly but a fielder or the ball landed fair and Mullins was thrown out at a base.
These account for all of Mullins’ plate appearances. Mullins has a batting average of BA = 157/608 = 0.258 and an on-base percentage of OBP = 0.318.
Slugging percentage
The slugging percentage, SLG, (SLuGging) is the total bases achieved on hits divided by at-bats:
SLG = TB/AB.
Here, TB or Total Bases, is the weighted sum
TB = 1B + 2*2B + 3*3B + 4*HR,
where
- 1B is the number of “singles” (hits where the batter makes it to 1st Base),
- 2B is the number of doubles,
- 3B is the number of triples, and
- HR denotes the number of Home Runs.
On-base Plus Slugging
With all these definitions under own belt, finally we are ready to compute “on-base plus slugging”, that is the on-base percentage plus slugging percentage:
OPS = OBP + SLG.
Example: Again, let’s consider Curtis Mullins. He had 1B = 105 singles, 2B = 32 doubles, 3B = 4 triples, and HR = 16 home runs, so his TB = 105+64+12+64 = 245. Therefore, his SLG = 245/608 = 0.403, so his on-base plus slugging is OPS = OBP + SLG = 0.318 + 0.403 = 0.721.
This finishes our discussion of OPS. I hope this helps explain it better. For more, see the OPS page at the MLB site or the wikipedia page for OPS.
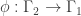 , where
, where 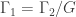 is a quotient graph obtained from some subgroup
is a quotient graph obtained from some subgroup 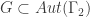 . The examples are for graphs having a small number of vertices (no more than 12). For the most part, we also focused on regular graphs with small degree (no more than 5). They were all computed using
. The examples are for graphs having a small number of vertices (no more than 12). For the most part, we also focused on regular graphs with small degree (no more than 5). They were all computed using 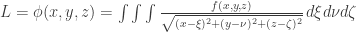
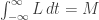







 (distictly labeled) cards, where
(distictly labeled) cards, where 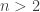 is an integer. The collection of all possible shuffles, or permutations, of this deck is denoted
is an integer. The collection of all possible shuffles, or permutations, of this deck is denoted 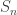 and called the symmetric group. The above discussion leads naturally to the following question(s).
and called the symmetric group. The above discussion leads naturally to the following question(s).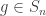 , write that element
, write that element 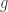 in disjoint cycle notation. Denote the lengths of the disjoint cycles occurring in
in disjoint cycle notation. Denote the lengths of the disjoint cycles occurring in 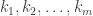 , where
, where 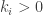 are integers forming a
are integers forming a 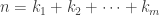 . Then the order of
. Then the order of 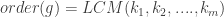 , where LCM denotes the
, where LCM denotes the 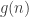 is the function that returns the maximum possible order of an element
is the function that returns the maximum possible order of an element 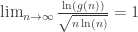 .
. 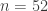 then note
then note 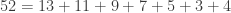 and that
and that 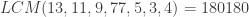 .
. to create the truncated tetrahedron
to create the truncated tetrahedron  (by essentially creating a triangle from each of these clipped corners – see below for the associated graph). Then just map each such triangle to the corresponding vertex of the tetrahedron. No, it’s not obvious because the map just described is not a covering. This post describes one way to think about how to construct any covering.
(by essentially creating a triangle from each of these clipped corners – see below for the associated graph). Then just map each such triangle to the corresponding vertex of the tetrahedron. No, it’s not obvious because the map just described is not a covering. This post describes one way to think about how to construct any covering.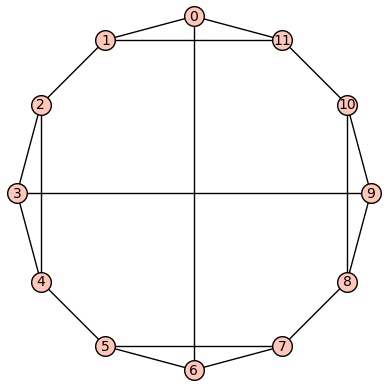

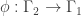 :
:
 – with no vertical multiplicities and all horizontal multiplicities equal to 1. These 24 harmonic morphisms of
– with no vertical multiplicities and all horizontal multiplicities equal to 1. These 24 harmonic morphisms of  are all coverings and there are no other harmonic morphisms.
are all coverings and there are no other harmonic morphisms. to be
to be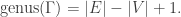
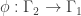 be a harmonic morphism from a graph
be a harmonic morphism from a graph  to a graph
to a graph  . Then
. Then![{\rm genus}(\Gamma_2)-1 = {\rm deg}(\phi)({\rm genus}(\Gamma_1)-1)+\sum_{x\in V_2} [m_\phi(x)+\frac{1}{2}\nu_\phi(x)-1].](https://s0.wp.com/latex.php?latex=%7B%5Crm+genus%7D%28%5CGamma_2%29-1+%3D+%7B%5Crm+deg%7D%28%5Cphi%29%28%7B%5Crm+genus%7D%28%5CGamma_1%29-1%29%2B%5Csum_%7Bx%5Cin+V_2%7D+%5Bm_%5Cphi%28x%29%2B%5Cfrac%7B1%7D%7B2%7D%5Cnu_%5Cphi%28x%29-1%5D.&bg=ffffff&fg=323232&s=0&c=20201002)
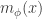 denotes the horizontal multiplicity and
denotes the horizontal multiplicity and  denotes the vertical multiplicity.
denotes the vertical multiplicity.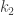 -regular and
-regular and  -regular.
-regular.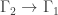 be a non-trivial harmonic morphism from a connected
be a non-trivial harmonic morphism from a connected 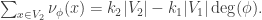
 denote the vertex set. There is (up to isomorphism) exactly one 4-regular connected graphs on 5 vertices. By Ore’s Theorem, this graph is Hamiltonian. By Euler’s Theorem, it is Eulerian.
denote the vertex set. There is (up to isomorphism) exactly one 4-regular connected graphs on 5 vertices. By Ore’s Theorem, this graph is Hamiltonian. By Euler’s Theorem, it is Eulerian. .
.
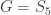 .)
.)
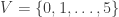 denote the vertex set. There is (up to isomorphism) exactly one 4-regular connected graphs on 6 vertices. By Ore’s Theorem, this graph is Hamiltonian. By Euler’s Theorem, it is Eulerian.
denote the vertex set. There is (up to isomorphism) exactly one 4-regular connected graphs on 6 vertices. By Ore’s Theorem, this graph is Hamiltonian. By Euler’s Theorem, it is Eulerian. having edge set:
having edge set:  .
.
 denote the vertex set. There are (up to isomorphism) exactly 2 4-regular connected graphs on 7 vertices. By Ore’s Theorem, these graphs are Hamiltonian. By Euler’s Theorem, they are Eulerian.
denote the vertex set. There are (up to isomorphism) exactly 2 4-regular connected graphs on 7 vertices. By Ore’s Theorem, these graphs are Hamiltonian. By Euler’s Theorem, they are Eulerian. . This is an Eulerian, Hamiltonian (by Ore’s Theorem), vertex transitive (but not edge transitive) graph.
. This is an Eulerian, Hamiltonian (by Ore’s Theorem), vertex transitive (but not edge transitive) graph.
 . This is an Eulerian, Hamiltonian graph (by Ore’s Theorem) which is neither vertex transitive nor edge transitive.
. This is an Eulerian, Hamiltonian graph (by Ore’s Theorem) which is neither vertex transitive nor edge transitive.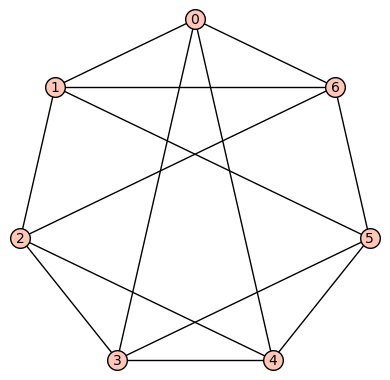
 denote the vertex set. There are (up to isomorphism) exactly six 4-regular connected graphs on 8 vertices. By Ore’s Theorem, these graphs are Hamiltonian. By Euler’s Theorem, they are Eulerian.
denote the vertex set. There are (up to isomorphism) exactly six 4-regular connected graphs on 8 vertices. By Ore’s Theorem, these graphs are Hamiltonian. By Euler’s Theorem, they are Eulerian. . This is vertex transitive but not edge transitive.
. This is vertex transitive but not edge transitive.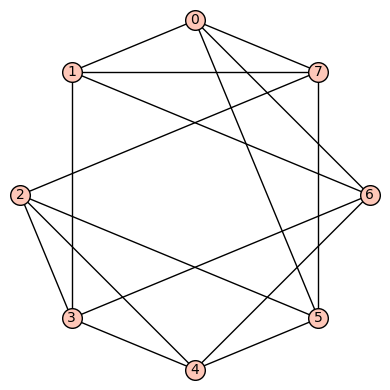
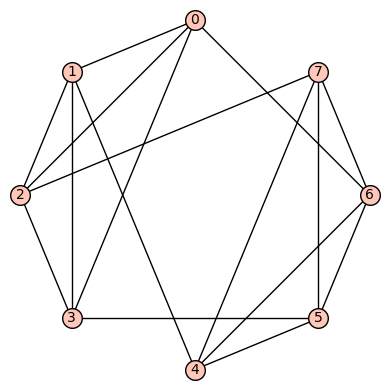
 and
and  .
.
 ,
, 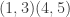 ,
,  ,
,  .
. . This is a strongly regular (with “trivial” parameters (8, 4, 0, 4)), vertex transitive, edge transitive graph.
. This is a strongly regular (with “trivial” parameters (8, 4, 0, 4)), vertex transitive, edge transitive graph.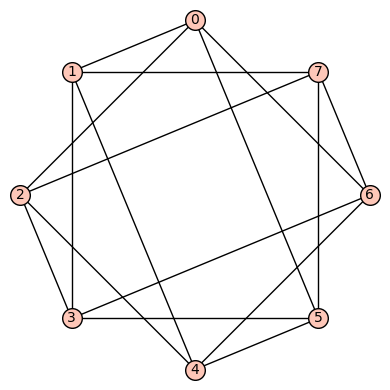
 and is generated by (5,6), (4,7), (3,4), (2,5), (1,2), (0,1)(2,3)(4,5)(6,7).
and is generated by (5,6), (4,7), (3,4), (2,5), (1,2), (0,1)(2,3)(4,5)(6,7). . This graph is not vertex transitive, nor edge transitive.
. This graph is not vertex transitive, nor edge transitive.
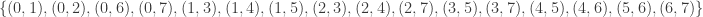 . This graph is not vertex transitive, nor edge transitive.
. This graph is not vertex transitive, nor edge transitive.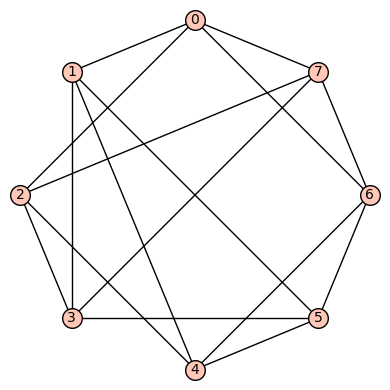
 having edge set:
having edge set: 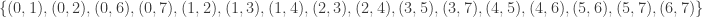 . This graph is not vertex transitive, nor edge transitive.
. This graph is not vertex transitive, nor edge transitive.
 denote the vertex set. There are (up to isomorphism) exactly 16 4-regular connected graphs on 9 vertices. Perhaps the most interesting of these is the strongly regular graph with parameters (9, 4, 1, 2) (also distance regular, as well as vertex- and edge-transitive). It has an automorphism group of cardinality 72, and is referred to as d4reg9-14 below.
denote the vertex set. There are (up to isomorphism) exactly 16 4-regular connected graphs on 9 vertices. Perhaps the most interesting of these is the strongly regular graph with parameters (9, 4, 1, 2) (also distance regular, as well as vertex- and edge-transitive). It has an automorphism group of cardinality 72, and is referred to as d4reg9-14 below. or the complete graph
or the complete graph 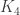 . However, both d4reg9-3 and d4reg9-14 not only have harmonic morphisms to
. However, both d4reg9-3 and d4reg9-14 not only have harmonic morphisms to  , they each may be regarded as a multicover of
, they each may be regarded as a multicover of 


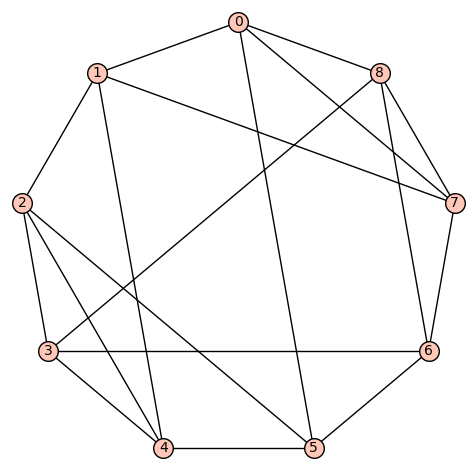



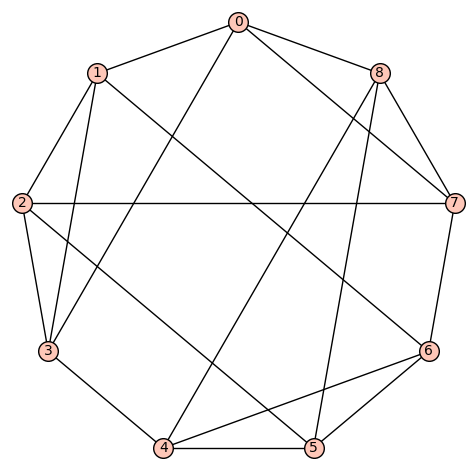
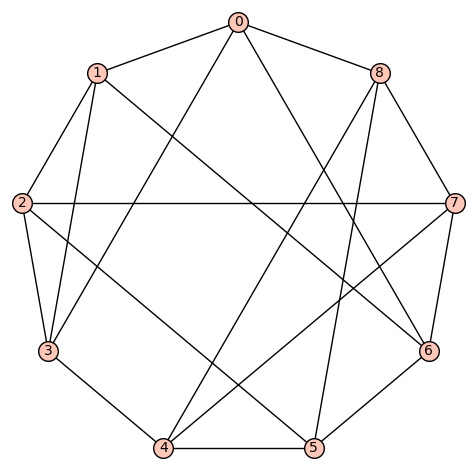



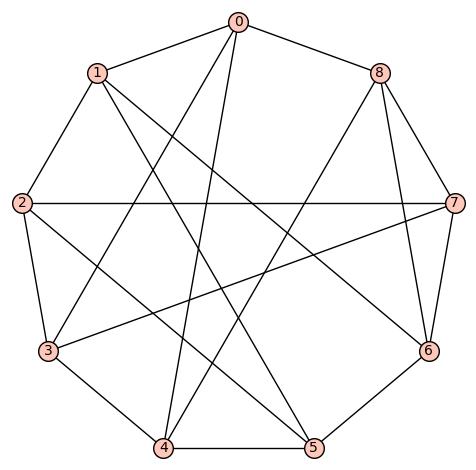

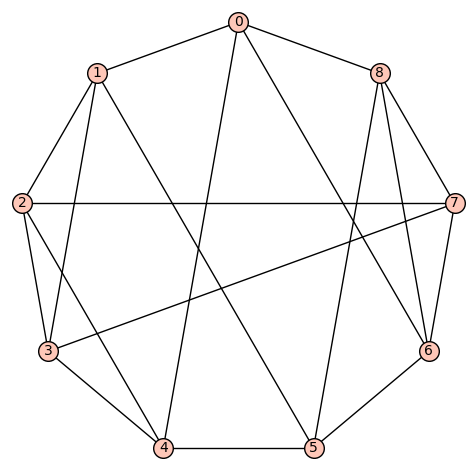

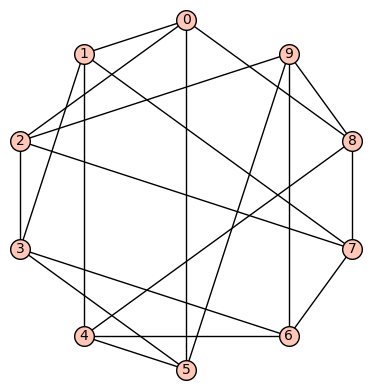
 denote the vertex set. There are (up to isomorphism) exactly 59 4-regular connected graphs on 10 vertices. One of these actually has an automorphism group of cardinality 1. According to SageMath: Only three of these are vertex transitive, two (of those 3) are symmetric (i.e., arc transitive), and only one (of those 2) is distance regular.
denote the vertex set. There are (up to isomorphism) exactly 59 4-regular connected graphs on 10 vertices. One of these actually has an automorphism group of cardinality 1. According to SageMath: Only three of these are vertex transitive, two (of those 3) are symmetric (i.e., arc transitive), and only one (of those 2) is distance regular. .
.
 .
.
 .
.

 .
.

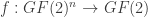 . Denote the
. Denote the  -vector space of such functions by
-vector space of such functions by  . We write an element of this space as
. We write an element of this space as 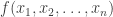 , where the variables
, where the variables  will be called coordinate variables. Let
will be called coordinate variables. Let
 . In this post, the cosets
. In this post, the cosets
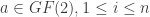 ). A function in
). A function in 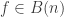 which (a) is constant along some coordinate hyperplane
which (a) is constant along some coordinate hyperplane  , (b) whose restriction
, (b) whose restriction 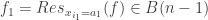 is constant along some coordinate hyperplane
is constant along some coordinate hyperplane 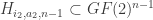 , (c) whose restriction
, (c) whose restriction  is constant along some coordinate hyperplane
is constant along some coordinate hyperplane 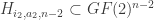 , (d) and so on. This “nested” inductive definition might seem complicated, but to a computer it’s pretty simple and, to boot, it requires little memory to store.
, (d) and so on. This “nested” inductive definition might seem complicated, but to a computer it’s pretty simple and, to boot, it requires little memory to store.  and
and 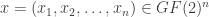 then let
then let 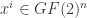 denote the vector whose i-th coordinate is flipped (bitwise). The sensitivity of
denote the vector whose i-th coordinate is flipped (bitwise). The sensitivity of  is
is . Roughly speaking, it’s the number of single-bit changes in
. Roughly speaking, it’s the number of single-bit changes in 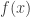 . The (maximum) sensitivity is the quantity
. The (maximum) sensitivity is the quantity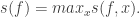 The block sensitivity is defined similarly, but you allow blocks of indices of coordinates to by flipped bitwise, as opposed to only one. It’s possible to
The block sensitivity is defined similarly, but you allow blocks of indices of coordinates to by flipped bitwise, as opposed to only one. It’s possible to 
You must be logged in to post a comment.