We may inquire into the possibility of undisclosed errors occurring in the transmittal of the sequence:

Invoking the theorem established in sections 4 and 5, and formulated at the close of section 5, we may assert:
-
(1) If not more than three errors are made in transmitting the fifteen letters of the sequence, and if the errors made affect the
only, the
being correctly transmitted, then the presence of error is certain to be disclosed.
-
(2) If not more than three errors are made, all told, but at least three of them affect the
chance of escaping disclosure.

These assertions result at once from the theorem referred to. But a closer study of the reference matrix employed in this example permits us to replace them by the following more satisfactory statements:
-
(1′)
If errors occur in not more than three of the fifteen elements of the sequence, and if at least one of the particular elements
is correctly transmitted, the presence of error will certainly be disclosed. But if exactly three errors are made, affecting presicely the elements
-in-
(
) chance of escaping disclosure.
-
(2′)
If more than three errors are made, then whatever the distribution of errors among the fifteen elements of the sequence, the presence of error will enjoy only a
(
) chance of escaping disclosure.
Assertions of this kind will be carefully established below, when a more important finite field is under consideration. The argument then made will be applicable in the case of any finite field. But it is worthwhile here to look more carefully into the exceptional distribution of errors which is italicized in (1′). This will help us note any weakness that ought to be avoided in the construction of reference matrices.
Suppose that exactly three errors are made, affecting precisely
These equations may be written:

But 


Etc. In this way, we find that the errors can escape disclosure if and only if

The error 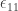



The trouble arises from the vanishing, in our reference matrix, of the two-rowed
determinant
Note that
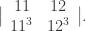
since 

From the fact that 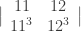
It will be advantageous, as shown more completely in subsequent sections, to employ reference matrices which contain the smallest possible number of vanishing determinants of any orders.
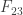 as the basis for a simple illustrative exercise in the actual procedure of checking. The general of the operations involved will thus be made clear, so far as modus operandi is concerned, and we shall be enabled to discuss more easily the pertinent mathematical details.
as the basis for a simple illustrative exercise in the actual procedure of checking. The general of the operations involved will thus be made clear, so far as modus operandi is concerned, and we shall be enabled to discuss more easily the pertinent mathematical details.
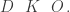
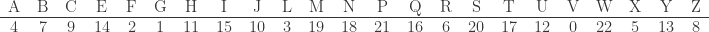




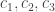 by using as reference matrix
by using as reference matrix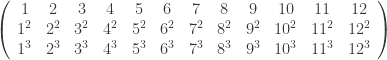

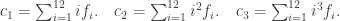
 , of the operant sequence
, of the operant sequence 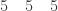
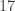 place a sheet of paper (or a ruler) under the second row
place a sheet of paper (or a ruler) under the second row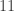 in column
in column  in column
in column  in column
in column 
 place a sheet of paper (or a ruler) under the third row
place a sheet of paper (or a ruler) under the third row in column
in column 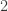 in column
in column 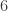 in column
in column 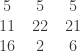
 . The complete scheme is readily found to be:
. The complete scheme is readily found to be:
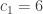 ,
, 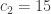 ,
,  .
.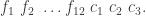


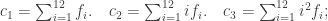
 , we may identify a Boolean function
, we may identify a Boolean function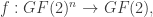
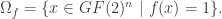
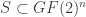 , let
, let 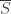 denote the set of complements
denote the set of complements  , for
, for  , and let
, and let 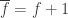 denote the complementary Boolean function. Note that
denote the complementary Boolean function. Note that
 denotes the complement of
denotes the complement of 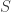 in
in  . Let
. Let
 is even (resp., odd). We may identify a vector in
is even (resp., odd). We may identify a vector in  Let
Let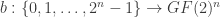
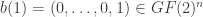 ).
).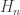 denote the $2^n\times 2^n$ Hadamard matrix defined by
denote the $2^n\times 2^n$ Hadamard matrix defined by 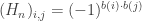 , for each
, for each 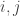 such that
such that 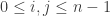 . Inductively, these can be defined by
. Inductively, these can be defined by
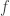 is defined to be the vector in
is defined to be the vector in  whose
whose 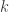 th component is
th component is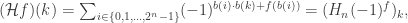
 as the column vector where the
as the column vector where the 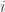 th component is
th component is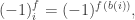
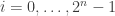 .
.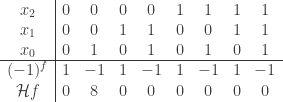
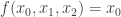 . It is even because
. It is even because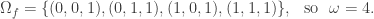
 be the Cayley graph of
be the Cayley graph of 
 so
so 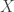 has no loops. In this case,
has no loops. In this case,  -regular graph having
-regular graph having  connected components, where
connected components, where
 , the set of neighbors
, the set of neighbors  of
of  is given by
is given by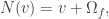
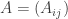 be the
be the 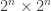 adjacency matrix of
adjacency matrix of 

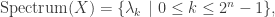
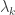 of the adjacency matrix
of the adjacency matrix 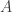 ) to the Walsh-Hadamard transform
) to the Walsh-Hadamard transform 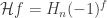 . Note that
. Note that  where
where 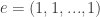 . She discovered the relationship
. She discovered the relationship

You must be logged in to post a comment.