This post simply collects some very well-known facts and observations in one place, since I was having a hard time locating a convenient reference.
Let 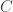 be the binary Hamming [7,4,3] code defined by the generator matrix
be the binary Hamming [7,4,3] code defined by the generator matrix 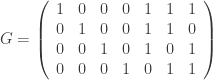 and check matrix
and check matrix 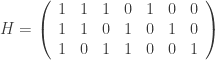 . In other words, this code is the row space of G and the kernel of H. We can enter these into Sage as follows:
. In other words, this code is the row space of G and the kernel of H. We can enter these into Sage as follows:
sage: G = matrix(GF(2), [[1,0,0,0,1,1,1],[0,1,0,0,1,1,0],[0,0,1,0,1,0,1],[0,0,0,1,0,1,1]])
sage: G
[1 0 0 0 1 1 1]
[0 1 0 0 1 1 0]
[0 0 1 0 1 0 1]
[0 0 0 1 0 1 1]
sage: H = matrix(GF(2), [[1,1,1,0,1,0,0],[1,1,0,1,0,1,0],[1,0,1,1,0,0,1]])
sage: H
[1 1 1 0 1 0 0]
[1 1 0 1 0 1 0]
[1 0 1 1 0 0 1]
sage: C = LinearCode(G)
sage: C
Linear code of length 7, dimension 4 over Finite Field of size 2
sage: C = LinearCodeFromCheckMatrix(H)
sage: LinearCode(G) == LinearCodeFromCheckMatrix(H)
True
The generator matrix gives us a one-to-one onto map  defined by
defined by 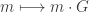 . Using this map, the codewords are easy to describe and enumerate:
. Using this map, the codewords are easy to describe and enumerate:
 .
.
Using this code, we first describe a guessing game you can play with even small children.
Number Guessing game: Pick an integer from 0 to 15. I will ask you 7 yes/no questions. You may lie once.
I will tell you when you lied and what the correct number is.
Question 1: Is n in {0,1,2,3,4,5,6,7}?
(Translated: Is 1st bit of Hamming_code(n) a 0?)
Question 2: Is n in {0,1,2,3,8,9,10,11}?
(Is 2nd bit of Hamming_code(n) a 0?)
Question 3: Is n in {0,1,4,5,8,9,12,13}?
(Is 3rd bit of Hamming_code(n) a 0?)
Question 4: Is n in {0,2,4,6,8,10,12,14} (ie, is n even)?
(Is 4th bit of Hamming_code(n) a 0?)
Question 5: Is n in {0,1,6,7,10,11,12,13}?
(Is 5th bit of Hamming_code(n) a 0?)
Question 6: Is n in {0,2,5,7,9,11,12,14}?
(Is 6th bit of Hamming_code(n) a 0?)
Question 7: Is n in {0,3,4,7,9,10,13,14}?
(Is 7th bit of Hamming_code(n) a 0?)
Record the answers in a vector (0 for yes, 1 for no): 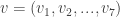 . This must be a codeword (no lies) or differ from a codeword by exactly one bit (1 lie). In either case, you can find n by decoding this vector.
. This must be a codeword (no lies) or differ from a codeword by exactly one bit (1 lie). In either case, you can find n by decoding this vector.
We discuss a few decoding algorithms next.
Venn diagram decoding:
We use a simple Venn diagram to describe a decoding method.
sage: t = var('t')
sage: circle1 = parametric_plot([10*cos(t)-5,10*sin(t)+5], (t,0,2*pi))
sage: circle2 = parametric_plot([10*cos(t)+5,10*sin(t)+5], (t,0,2*pi))
sage: circle3 = parametric_plot([10*cos(t),10*sin(t)-5], (t,0,2*pi))
sage: text1 = text("$1$", (0,0))
sage: text2 = text("$2$", (-6,-2))
sage: text3 = text("$3$", (0,7))
sage: text4 = text("$4$", (6,-2))
sage: text5 = text("$5$", (-9,9))
sage: text6 = text("$6$", (9,9))
sage: text7 = text("$7$", (0,-9))
sage: textA = text("$A$", (-13,13))
sage: textB = text("$B$", (13,13))
sage: textC = text("$C$", (0,-17))
sage: text_all = text1+text2+text3+text4+text5+text6+text7+textA+textB+textC
sage: show(circle1+circle2+circle3+text_all,axes=false)
This gives us the following diagram:

Decoding algorithm:
Suppose you receive 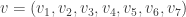 .
.
Assume at most one error is made.
Decoding process:
-
Place
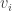 in region i of the Venn diagram.
in region i of the Venn diagram.
-
For each of the circles A, B, C, determine if the sum of the bits in four regions add up to 0 or to 1. If they add to 1, say that that circle has a “parity failure”.
-
The error region is determined form the following table.

For example, suppose v = (1,1,1,1,1,0,1). The filled in diagram looks like

This only fails in circle B, so the table says (correctly) that the error is in the 6th bit. The decoded codeword is 
Next, we discuss a decoding method based on the Tanner graph.
Tanner graph for hamming 7,4,3 code
The above Venn diagram corresponds to a bipartite graph, where the left “bit vertices” (1,2,3,4,5,6,7) correspond to the coordinates in the codeword and the right “check vertices” (8,9,10) correspond to the parity check equations as defined by the check matrix. This graph corresponds to the above Venn diagram, where the check vertices 8, 9, 10 were represented by circles A, B, C:
sage: Gamma = Graph({8:[1,2,3,5], 9:[1,2,4,6], 10:[1,3,4,7]})
sage: B = BipartiteGraph(Gamma)
sage: B.show()
sage: B.left
set([1, 2, 3, 4, 5, 6, 7])
sage: B.right
set([8, 9, 10])
sage: B.show()
This gives us the graph in the following picture:

Decoding algorithm:
Suppose you receive .
Assume at most one error is made.
Decoding process:
-
Place at the vertex i on the left side of the bipartite graph.
-
For each of the check vertices 8,9,10 on the right side of the graph, determine of the if the sum of the bits in the four left-hand vertices connected to it add up to 0 or to 1. If they add to 1, we say that that check vertex has a “parity failure”.
-
Those check vertices which do not fail are connected to bit vertices which we assume are correct. The remaining bit vertices
connected to check vertices which fail are to be determined (if possible) by solving the corresponding check equations.
check vertex 8: 
check vertex 9: 
check vertex 10: 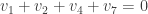
Warning: This method is not guaranteed to succeed in general. However, it does work very efficiently when the check matrix H is “sparse” and the number of 1’s in each row and column is “small.”
For example, suppose v = (1,1,1,1,1,0,1). The check vertex 9 fails its parity check, but vertex 8 and 10 do not. Therefore, only bit vertex 6 is unknown, since vertex 6 is the only one not connected to 8 and 10. This tells us that the decoding codeword is 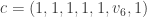 , for some unknown
, for some unknown  . We solve for this unknown using the check vertex equation , giving us
. We solve for this unknown using the check vertex equation , giving us  . The decoded codeword is
. The decoded codeword is 
This last example was pretty simple, so let’s try  . In this case, we know the vertices 9 and 10 fail, so
. In this case, we know the vertices 9 and 10 fail, so  . We solve using
. We solve using
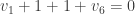

This simply tells us  . By majority vote, we get
. By majority vote, we get  .
.

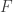
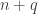
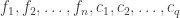
 errors
errors 
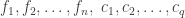

 errors which affect the
errors which affect the 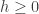 errors which affect the
errors which affect the 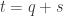 . Then, to avoid discussing again the case already considered, we assume that at least one of the two integers
. Then, to avoid discussing again the case already considered, we assume that at least one of the two integers 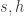
 .
. , affecting the
, affecting the 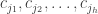 . Without loss in generality, we may assume that the
. Without loss in generality, we may assume that the  errors affecting the
errors affecting the  , so that the first
, so that the first 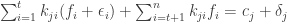
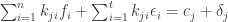

 and where
and where  in
in 
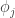 denotes a polynomial in the errors
denotes a polynomial in the errors  .
.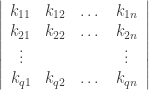

 , be equal to zero, contrary to hypothesis.
, be equal to zero, contrary to hypothesis. is different from
is different from  are uniquely determined as functions of the
are uniquely determined as functions of the  :
:
 being, of course, rational functions. But, by assumption, all of the $\delta_j$, except
being, of course, rational functions. But, by assumption, all of the $\delta_j$, except  , vanish. Hence
, vanish. Hence  ) is a rational function of
) is a rational function of  .
. errors, is to check up, so that the presence of error can escape detection,
errors, is to check up, so that the presence of error can escape detection,  errors.
errors. denote the total number of elements in the finite algebraic field
denote the total number of elements in the finite algebraic field  values — an error with the value
values — an error with the value 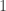 chance in
chance in 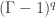 of being accidentally adjusted so as to escape detection.
of being accidentally adjusted so as to escape detection. errors occur among the
errors occur among the  , the errors being all of accidental telegraphic origin, the presence of error will infallibly be disclosed if
, the errors being all of accidental telegraphic origin, the presence of error will infallibly be disclosed if  ; and will enjoy a
; and will enjoy a  is greater than
is greater than 
 ,
, 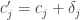 , where
, where 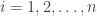 ,
,  , the errors
, the errors  (resp.,
(resp., 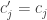 ).
).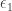 ,
,  . Since the
. Since the 
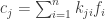 . Hence the message will fail to check, and the presence of error will be disclosed, unless the
. Hence the message will fail to check, and the presence of error will be disclosed, unless the 
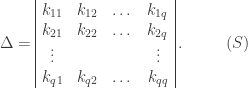
 , for
, for 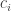 , and not more than
, and not more than  elements
elements 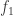 ,
,  ,
,  ,
,  in a finite algebraic field
in a finite algebraic field 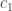 ,
,  ,
,  upon the sequence
upon the sequence 
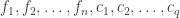

 .
. in the system of equations
in the system of equations 
 denote the value, in
denote the value, in 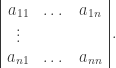
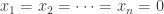
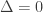 .
.
 be less than
be less than 

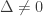 (Footnote: The case
(Footnote: The case  does not concern us.) then the system of equations
does not concern us.) then the system of equations 
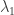 ,
,  ,
, 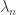 , which are not necessarily distinct but certainly are not all equal to zero, such that
, which are not necessarily distinct but certainly are not all equal to zero, such that


 , where
, where 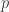 denotes a prime positive integer greater than
denotes a prime positive integer greater than  denotes a positive integer. Conversely, if
denotes a positive integer. Conversely, if 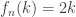 , if k <= n/2 and
, if k <= n/2 and  , if
, if  Let
Let  , where
, where 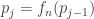 and
and 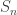 is the symmetric group of order
is the symmetric group of order 



You must be logged in to post a comment.