This page contains information on
- which mathematicians (which we define as someone who has earned a PhD or equivalent in Mathematics) play(ed) chess at the International Master level or above (in OTB or correspondence or problem composing), and
- how to get papers on mathematical chess problems.
Similar pages are here and here and here and here.
Mathematicians who play(ed) chess
- Conel Hugh O’Donel Alexander (1909-1974), late British chess champion. Alexander may not have had a PhD in mathematics but taught mathematics and he did mathematical work during WWII (code and cryptography), as did the famous Soviet chess player David Bronstein (see the book Kahn, Kahn on codes). He was the strongest English player after WWII, until Jonathan Penrose appeared.
- Adolf Anderssen (1818-1879). Pre World Championships but is regarded as the strongest player in the world between 1859 and 1866. He received a degree (probably not a PhD) in mathematics from Breslau University and taught mathematics at the Friedrichs gymnasium from 1847 to 1879. He was promoted to Professor in 1865 and was given an honorary doctorate by Breslau (for his accomplishments in chess) in 1865.
- Magdy Amin Assem (195?-1996) specialized in p-adic representation theory and harmonic analysis on p-adic reductive groups. He published several important papers before a ruptured aneurysm tragically took his life. He was IM strength (rated 2379) in 1996.
- Gedeon Barcza (1911-1986), pronounced bartsa, was a Hungarian professor of mathematics and a chess grandmaster. The opening 1.Nf3 d5 2.g3 is called the Barcza System. The opening 1.e4 e6 2.d4 c5 is known as the Barcza-Larsen Defense.
- Ludwig Erdmann Bledow (1795-1846) was a German professor of mathematics (PhD). He founded the first German chess association, Berliner Schachgesellschaft, in 1827. He was the first person to suggest an international chess tournament (in a letter to von der Lasa in 1843). His chess rating is not known but he did at one point win a match against Adolf Anderssen.
- Robert Coveyou (1915 – 1996) completed an M.S. degree in Mathematics, and joined the Oak Ridge National Laboratory as a research mathematician. He became a recognized expert in pseudo-random number generators. He is known for the quotation “The generation of random numbers is too important to be left to chance,” which is based on a title of a paper he wrote. An excellent tournament chess player, he was Tennessee State Champion eight times.
- Nathan Divinsky (1925-2012) earned a PhD in Mathematics in 1950 from the University of Chicago and was a mathematics professor at the University of British Columbia in Vancouver. He tied for first place in the 1959 Manitoba Open.
- Noam Elkies (1966-), a Professor of Mathematics at Harvard University specializing in number theory, is a study composer and problem solver (ex-world champion). Prof. Elkies, at age 26, became the youngest scholar ever to have attained a tenured professorship at Harvard. One of his endgame studies is mentioned, for example, in the book Technique for the tournament player, by GM Yusupov and IM Dvoretsky, Henry Holt, 1995. He wrote 11 very interesting columns on Endgame Exporations (posted by permission).
Some other retrograde chess constructions of his may be found at the interesting Dead Reckoning web site of Andrew Buchanan.
See also Professor Elkies’s very interesting Chess and Mathematics Seminar pages. - Thomas Ernst earned a Ph.D. in mathematics from Uppsala Univ. in 2002 and does research in algebraic combinatorics with applications to mathematical physics. His chess rating is about 2400 (FIDE).
- Machgielis (Max) Euwe (1901-1981), World Chess Champion from 1935-1937, President of FIDE (Fédération Internationale des Echecs) from 1970 to 1978, and arbitrator over the turbulent Fischer – Spassky World Championship match in Reykjavik, Iceland in 1972. I don’t know as many details of his mathematical career as I’d like. One source gives: PhD (or actually its Dutch equivalent) in Mathematics from Amsterdam University in 1926. Another gives: Doctorate in philosophy in 1923 and taught as a career. Published an important paper on the mathematics of chess “Mengentheoretische Betrachtungen uber das Schachspiel”. This paper lead to a rule change in chess regarding the 3-times repetition draw.

- Ed Formanek (194?-), International Master. Ph.D. Rice University 1970. Retired from the mathematics faculty at Penn State Univ. Worked primarily in matrix theory and representation theory.
- Stephen L. Jones is an attorney in LA, but when younger, taught math in the UMass system and spent a term as a member of the Institute for Advanced Study in Princeton NJ. He is one rung below the level of International Master at over the board chess; in correspondence chess, he has earned two of the three norms needed to become a Grandmaster.
- Charles Kalme (1939-2002), earned his master title in chess at 15, was US Junior champ in 1954, 1955, US Intercollegiate champ in 1957, and drew in his game against Bobby Fischer in the 1960 US championship. In 1960, he also was selected to be on the First Team All-Ivy Men’s Soccer team, as well as the US Student Olympiad chess team. (Incidently, it is reported that this team, which included William Lombary on board one, did so well against the Soviets in their match that Boris Spassky, board one on the Soviet team, was denied forieng travel for two years as punishment.) In 1961 graduated 1st in his class at the Moore School of Electrical Engineering, The University of Pennsylvania, in Philadelphia. He also received the Cane award (a leadership award) that year. After getting his PhD from NYU (advisor Lipman Bers) in 1967 he to UC Berkeley for 2 years then to USC for 4-5 years. He published 2 papers in mathematics in this period, “A note on the connectivity of components of Kleinian groups”, Trans. Amer. Math. Soc. 137 1969 301–307, and “Remarks on a paper by Lipman Bers”, Ann. of Math. (2) 91 1970 601–606. He also translated Siegel and Moser, Lectures on celestial mechanics, Springer-Verlag, New York, 1971, from the German original. He was important in the early stages of computer chess programming. In fact, his picture and annotations of a game were featured in the article “An advice-taking chess computer” which appeared in the June 1973 issue of Scientific American. He was an associate editor at Math Reviews from 1975-1977 and then worked in the computer industry. Later in his life he worked on trying to bring computers to elementary schools in his native Latvia A National Strategy for Bringing Computer Literacy to Latvian Schools. His highest chess rating was acheived later in his life during a “chess comeback”: 2458.
Here is his game against Bobby Fischer referred to above:[Event “?”]
[Site “New York ch-US”]
[Date “1960.??.??”]
[Round “3”]
[White “Fischer, Robert J”]
[Black “Kalme, Charles”]
[Result “1/2-1/2”]
[NIC “”]
[Eco “C92”]
[Opening “Ruy Lopez, Closed, Ragozin-Petrosian (Keres) Variation”]
1.e4 e5 2.Nf3 Nc6 3.Bb5 a6 4.Ba4 Nf6 5.O-O Be7 6.Re1 b5 7.Bb3 O-O 8.c3 d6 9.h3 Nd7 10.a4 Nc5 11.Bd5 Bb7 12.axb5 axb5 13.Rxa8 Qxa8 14.d4 Nd7 15.Na3 b4 16.Nc4 exd4 17.cxd4 Nf6 18.Bg5 Qd8 19.Qa4 Qa8 20.Qxa8 Rxa8 21.Bxf6 Bxf6 22.e5 dxe5 23.Ncxe5 Nxe5 24.Bxb7 Nd3 25.Bxa8 Nxe1 26.Be4 b3 27.Nd2 1/2-1/2 - Miroslav Katetov (1918 -1995) earned his PhD from Charles Univ in 1939. Katetov was IM chess player (earned in 1951) and published about 70 research papers, mostly from topology and functional analysis.
- Martin Kreuzer (1962-), CC Grandmaster, is rated over 2600 in correspondence chess (ICCF, as of Jan 2000). His OTB rating is over 2300. His specialty is computational commutative algebra and applications. Here is a recent game of his:
Kreuzer, M – Stickler, A
[Eco “B42”]
[Opening “Sicilian, Kan”]
1.e4 c5 2.Nf3 e6 3.d4 cxd4 4.Nxd4 a6 5.Bd3 Nc6 6.c3 Nge7 7.0-0 Ng6 8.Be3 Qc7 9.Nxc6 bxc6 10.f4 Be7 11.Qe2 0-0 12.Nd2 d5 13.g3 c5 14.Nf3 Bb7 15.exd5 exd5 16.Rae1 Rfe8 17.f5 Nf8 18.Qf2 Nd7 19.g4 f6 20.g5 fxg5 21.Nxg5 Bf6 22.Bf4 Qc6 23.Re6 Rxe6 24.fxe6 Bxg5 25.Bxg5 d4 26.Qf7+ Kh8 27.Rf3 Qd5 28.exd7 Qxg5+ 29.Rg3 Qe5 30.d8=Q+ Rxd8 31.Qxb7 Rf8 32.Qe4 Qh5 33.Qe2 Qh6 34.cxd4 cxd4 35.Bxa6 Qc1+ 36.Kg2 Qc6+ 37.Rf3 Re8 38.Qf1 Re3 39.Be2 h6 40.Kf2 Re8 41.Bd3 Qd6 42.Kg1 Kg8 43.a3 Qe7 44.b4 Ra8 45.Qc1 Qd7 46.Qf4 1-0 - Emanuel Lasker (1868-1941), World Chess Champion from 1894-1921, PhD (or more precisely its German equivalent) in Mathematics from Erlangen Univ in 1902. Author of the influential paper “Zur theorie der moduln und ideale,” Math. Ann. 60(1905)20-116, where the well-known Lasker-Noether Primary Ideal Decomposition Theorem in Commutative Algebra was proven (it can be downloaded for free here). Lasker wrote and published numerous books and papers on mathematics, chess (and other games), and philosophy.

- Vania Mascioni, former IECG Chairperson (IECG is the Internet Email Chess Group), is rated 2326 by IECG (as of 4-99). His area is Functional Analysis and Operator Theory.
- A. Jonathan Mestel, grandmaster in over-the-board play and in chess problem solving, is an applied mathematician specializing in fluid mechanics and is the author of numerous research papers. He is on the mathematics faculty of the Imperial College in London.
- Walter D. Morris (196?-), International Master. Currently on the mathematics faculty at George Mason Univ in Virginia.
- Karsten Müller earned the Grandmaster title in 1998 and a PhD in mathematics in 2002 at the University of Hamburg.
- John Nunn (1955-), Chess Grandmaster, D. Phil. (from Oxford Univ.) in 1978 at the age of 23. His PhD thesis is in algebraic topology. Nunn is also a GM chess problem solver.
- Hans-Peter Rehm (1942-), earned his PhD in Mathematics from Karlsruhe Univ. (1970) then taught there for many years. He is a grandmaster of chess composition. He has written several papers in mathematics, such as “Prime factorization of integral Cayley octaves”, Ann. Fac. Sci. Toulouse Math (1993), but most in differential algebra, his specialty. A collection of his problems has been published as: Hans+Peter+Rehm=Schach Ausgewählte Schachkompositionen & Aufsätze (= selected chess problems and articles), Aachen 1994.
- Kenneth W. Regan, Professor of Computer Science at the State Univ. of New York Buffalo, is currently rated 2453. His research is in computational complexity, a field of computer science which has a significant mathematical component.
- Jakob Rosanes obtained his mathematics doctorate from the Univ. of Breslau in 1865 where he taught for the rest of his life. In the 1860s he played a match against A. Anderssen which ended with 3 wins, 3 losses, and 1 draw.
- Jan Rusinek (1950-) obtained his mathematics PhD in 1978 and earned a Grandmaster of Chess Composition in 1992.
- Jon Speelman (1956-) is an English Grandmaster chess player and chess writer. He earned his PhD in mathematics from Oxford.

Others that might go on this list would be Henry Ernest Atkins (he taught mathematics but never got a PhD, but won the British Chess Championship 9 times in the early 1900s), Andrew Kalotay (who earned a PhD in statistics in 1968 from the Univ of Toronto, and was a Master level chess player but was not formally given an IM chess ranking), Kenneth Rogoff (has a PhD in economics but has published statistics research papers and is a GM in chess), and Duncan Suttles (in the 1960s he started but never finished his PhD in mathematics, but is a chess GM).
Papers about mathematical problems in chess
- Timothy Chow, “A Short Proof of the Rook Reciprocity Theorem”, in volume 3, 1996, of the Electronic Journal of Combinatorics.
- Noam Elkies, “On numbers and endgames: Combinatorial game theory in chess endgames”, in 1996 “Games of No Chance” = Proceedings of the workshop on combinatorial games held July’94 at MSRI. Available from MSRI Publications — Volume 29 or Noam Elkies’ site.
- Noam Elkies and Richard Stanley, “Chess and Mathematics” book (in preparation).
- Awani Kumar, “Knight’s Tours in 3 Dimensions”, in The Games and Puzzles Journal The On-line Journal for Mathematical Recreations, Issue 43, January-April 2006.
- Richard M. Low and Mark Stamp, “King and Rook Vs. King on a Quarter-Infinite Board“, in Integers, volume 6(2006).
- Igor Rivin, Ilan Vardi, Paul Zimmermann, “The N-queens problem“, American Mathematical Monthly 101 (1994), no. 7, 629-639.
- Lewis Benjamin Stiller, “Exploiting symmetries on parallel architecture”, PhD thesis, CS Dept, Johns Hopkins Univ. 1995 Closely related is his Games of No Chance paper, “Multilinear Algebra and Chess Endgames“.
- Mario VELUCCHI’s math chess problems
- Wikipedia’s, Eight queens puzzle.
- Herbert S. Wilf, “The Problem of the Kings”, and Michael Larsen, “The Problem of Kings”, both in volume 2, 1995, of the Electronic Journal of Combinatorics.
- Papers on odd king tours by D. Joyner and M. Fourte (appeared in the J. of Rec. Math., 2003) and even king tours by M. Kidwell and C. Bailey (in Mathematics Magazine, vol 58, 1985).
- Lesson 3 in the chess lessons by Coach Epshteyn at UMBC.
Thanks to Christoph Bandelow, Max Burkett, Elaine Griffith, Hannu Lehto, John Kalme, Ewart Shaw, Richard Stanley, Will Traves, Steven Dowd, Z. Kornin, Noam Elkies and Hal Bogner for help and corrections on this page. This page is an updated version of that page and the other page.
 on the vector of water quantities, indexed by the students. I think that in general the answer to Q1 is “yes.” Here is the Sage code in the case of 3 students:
on the vector of water quantities, indexed by the students. I think that in general the answer to Q1 is “yes.” Here is the Sage code in the case of 3 students: has eigenvalue
has eigenvalue  with eigenvector
with eigenvector 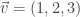 . This means that in the case that student 1 has 3 ounces of water, student 2 has 2 ounces of water, student 3 has 1 ounce of water, if each student shares water as explained in the problem, at the end of the process, they will each have the same amount as they started with.
. This means that in the case that student 1 has 3 ounces of water, student 2 has 2 ounces of water, student 3 has 1 ounce of water, if each student shares water as explained in the problem, at the end of the process, they will each have the same amount as they started with. is not prime.
is not prime.
 ,
,  represent respectively the zero and the unit elements of the field.
represent respectively the zero and the unit elements of the field.

 an arbitrary element of this field, we see that negatives and reciprocals of the elements of the field are as shown in the scheme:
an arbitrary element of this field, we see that negatives and reciprocals of the elements of the field are as shown in the scheme:



 . By the usual methods, it is quickly found that one solution is (
. By the usual methods, it is quickly found that one solution is ( ,
,  ,
,  ). The general solution is (
). The general solution is ( ,
,  ,
, 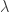 denotes an element of the field.
denotes an element of the field.
 ,
, 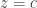 .
.
 . It may be observed in passing that if
. It may be observed in passing that if 
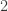 , then in that field
, then in that field  .
.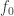 ,
, 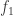 ,
, 
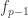 be
be 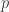 symbols or marks, and let
symbols or marks, and let 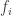 . To this end, we regard $f_i$ as associated with the integer
. To this end, we regard $f_i$ as associated with the integer 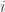 which we shall call the “affix” of the mark
which we shall call the “affix” of the mark  is given by the formula
is given by the formula
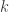 is the smallest non-negative integer satisfying
is the smallest non-negative integer satisfying
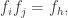
 is the smallest non-negative integer satisfying
is the smallest non-negative integer satisfying

 elements of our field then
elements of our field then
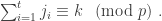


 elements. An addition table is not needed. The multiplication table is as follows:
elements. An addition table is not needed. The multiplication table is as follows:
 are negatives —
are negatives —  ,
,  — when
— when  . In the present example, therefore, two marks
. In the present example, therefore, two marks  are negatives if
are negatives if
 are momentarily regarded as ordinary integers of familiar arithmetic.
are momentarily regarded as ordinary integers of familiar arithmetic.
 . We shall use it in illustrating our checking operations.
. We shall use it in illustrating our checking operations.
 , so that we may write
, so that we may write


 being irreducible in
being irreducible in 
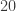 is not the square of an element in
is not the square of an element in  , we may identify a Boolean function
, we may identify a Boolean function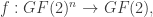
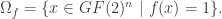
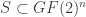 , let
, let 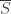 denote the set of complements
denote the set of complements  , for
, for  , and let
, and let 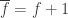 denote the complementary Boolean function. Note that
denote the complementary Boolean function. Note that
 denotes the complement of
denotes the complement of 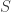 in
in  . Let
. Let
 is even (resp., odd). We may identify a vector in
is even (resp., odd). We may identify a vector in  Let
Let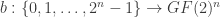
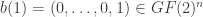 ).
).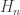 denote the $2^n\times 2^n$ Hadamard matrix defined by
denote the $2^n\times 2^n$ Hadamard matrix defined by 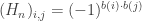 , for each
, for each 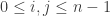 . Inductively, these can be defined by
. Inductively, these can be defined by
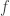 is defined to be the vector in
is defined to be the vector in  whose
whose 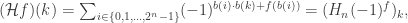
 as the column vector where the
as the column vector where the 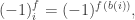
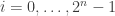 .
.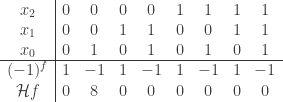
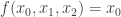 . It is even because
. It is even because
 be the Cayley graph of
be the Cayley graph of 
 so
so  has no loops. In this case,
has no loops. In this case,  -regular graph having
-regular graph having  connected components, where
connected components, where
 , the set of neighbors
, the set of neighbors  of
of  is given by
is given by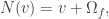
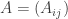 be the
be the 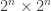 adjacency matrix of
adjacency matrix of 

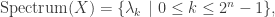
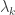 of the adjacency matrix
of the adjacency matrix 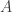 ) to the Walsh-Hadamard transform
) to the Walsh-Hadamard transform 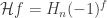 . Note that
. Note that  where
where 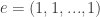 . She discovered the relationship
. She discovered the relationship
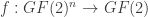 be a Boolean function. (We identify
be a Boolean function. (We identify  with either the real numbers
with either the real numbers 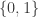 or the binary field
or the binary field  . Hopefully, the context makes it clear which one is used.)
. Hopefully, the context makes it clear which one is used.) on
on  , we say
, we say  whenever we have
whenever we have  ,
,  , …,
, …, 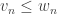 . A Boolean function is called monotone (increasing) if whenever we have
. A Boolean function is called monotone (increasing) if whenever we have 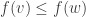 .
. 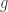 are monotone then (a)
are monotone then (a)  is also monotone, and (b)
is also monotone, and (b)  . (Overline means bit-wise complement.)
. (Overline means bit-wise complement.) is the least support of
is the least support of 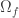 which are smallest in the partial ordering
which are smallest in the partial ordering  on
on  ,
, 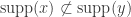 and
and 


 .
. . Then
. Then

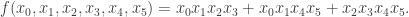
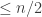 ?
?
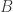 are matrices of the same size. Then
are matrices of the same size. Then 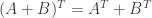 .
.


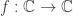 is a function, the function
is a function, the function 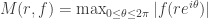 is called the maximum modulus of
is called the maximum modulus of 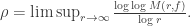
 then we have
then we have  . We say
. We say 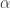 if there is a curve
if there is a curve  such that
such that 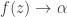 as
as 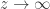 on
on  ?” In his PhD thesis, Ahlfors proved the answer is yes.
?” In his PhD thesis, Ahlfors proved the answer is yes.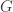 is a discrete subgroup of
is a discrete subgroup of  The group
The group  of
of  complex matrices of determinant
complex matrices of determinant  . Consider
. Consider  to itself. The orbit
to itself. The orbit  of a point
of a point 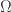 of a (finitely generated) Kleinian group
of a (finitely generated) Kleinian group 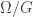 of finite type. In other words,
of finite type. In other words, 


 and let
and let  be a subset of the boundary of
be a subset of the boundary of  and known as the harmonic measure at
and known as the harmonic measure at  of
of  on the whole boundary, then, by the maximum principle,
on the whole boundary, then, by the maximum principle,  , for every interior point
, for every interior point  .
.
 is the extremal distance between
is the extremal distance between 
 be the Hilbert space of holomorphic functions in the unit disk which belong to
be the Hilbert space of holomorphic functions in the unit disk which belong to  on
on  . Let
. Let 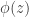 , i.e.
, i.e.  ,
,  a.e., such that
a.e., such that  if and only if
if and only if 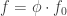 , with $f_0\in H^2$.
, with $f_0\in H^2$. be the given sequence of "primes" and let
be the given sequence of "primes" and let 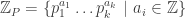
 and
and 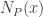 be the corresponding counting functions. Then
be the corresponding counting functions. Then  , implies the prime-number theorem
, implies the prime-number theorem  if
if 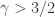 but in a sense not if
but in a sense not if  .
. satisfies
satisfies  are such that
are such that  , then Olofsson [O] conjectures that
, then Olofsson [O] conjectures that
 .
.
 be an orientation-preserving homeomorphism between open sets in the plane. If
be an orientation-preserving homeomorphism between open sets in the plane. If  -quasiconformal if the derivative of at every point maps circles to ellipses with eccentricity bounded by
-quasiconformal if the derivative of at every point maps circles to ellipses with eccentricity bounded by 
 increases for
increases for  ,
,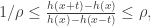
")
 or
or  or
or  , clockwise or counterclockwise. The effect of this is that the centers of the faces do not change. If you imagine the front face of the cube as always facing you and that you are holding the cube with your right hand on the right face, the the total number
, clockwise or counterclockwise. The effect of this is that the centers of the faces do not change. If you imagine the front face of the cube as always facing you and that you are holding the cube with your right hand on the right face, the the total number 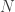 of different positions that the cube could be scrambled is
of different positions that the cube could be scrambled is 
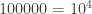 straws in a haystack. In other words, finding a needle in a haystack is
straws in a haystack. In other words, finding a needle in a haystack is  (“ten thousand billion”) times easier. How does it compare to the gross domestic product of the United States economy? This number
(“ten thousand billion”) times easier. How does it compare to the gross domestic product of the United States economy? This number 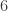 petabytes, or
petabytes, or  . Imagine having to search through this. The “Rubik’s cube database” is over
. Imagine having to search through this. The “Rubik’s cube database” is over  times larger. This number of cube positions is a very big number. This is what Tom is trying to search through.
times larger. This number of cube positions is a very big number. This is what Tom is trying to search through. possible positions, one might think that God’s number could be very large.
possible positions, one might think that God’s number could be very large. 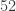 moves or less [C20]. Here is a table of progress since then.
moves or less [C20]. Here is a table of progress since then.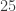 -move upper bound to show, in the face turn metric, every position can be solved in
-move upper bound to show, in the face turn metric, every position can be solved in  moves.
moves.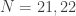 . This meant God’s numbr was
. This meant God’s numbr was  . On the other hand, the “superflip” position is known to take
. On the other hand, the “superflip” position is known to take  hair cells. There is no way to surgically implant
hair cells. There is no way to surgically implant  quarter turn moves, namely, the “superflip with 4 spot” position (the position of the Rubik’s cube where the corners are correct, and all edges are correctly placed but “flipped,” and 4 of the 6 corners are permuted) also established in 1995 by Michael Reid. In the quarter turn metric, the answer is unknown at this time.
quarter turn moves, namely, the “superflip with 4 spot” position (the position of the Rubik’s cube where the corners are correct, and all edges are correctly placed but “flipped,” and 4 of the 6 corners are permuted) also established in 1995 by Michael Reid. In the quarter turn metric, the answer is unknown at this time. ")
 (
(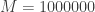 ). Player 2 asks a series of “yes/no questions” in an attempt to determine that number. Player 1 can lie at most
). Player 2 asks a series of “yes/no questions” in an attempt to determine that number. Player 1 can lie at most  times (
times ( is fixed). Assuming best possible play on both sides, what is the minimum number of “yes/no questions” Player 2 must ask to (in general) be able to correctly determine the number Player 1 selected?
is fixed). Assuming best possible play on both sides, what is the minimum number of “yes/no questions” Player 2 must ask to (in general) be able to correctly determine the number Player 1 selected? .
.


 into half and find which half the number lies in. Discard the one it does not lie in.
into half and find which half the number lies in. Discard the one it does not lie in. into half and find which half the number lies in. Discard the one it does not lie in.
into half and find which half the number lies in. Discard the one it does not lie in. into half and find which half the number lies in. Discard the one it does not lie in.
into half and find which half the number lies in. Discard the one it does not lie in.
 , where
, where  . The 20 questions are:
. The 20 questions are: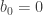 ?
? ?
?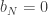 ?
? ‘s from this (since each
‘s from this (since each  is either 0 or 1).
is either 0 or 1). 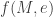 . If feedback is not allowed, call this minimum number
. If feedback is not allowed, call this minimum number  .
.
 ) but an efficient algorithm for determining the “yes/no questions” Player 2 should ask.
) but an efficient algorithm for determining the “yes/no questions” Player 2 should ask.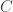 of
of  , where
, where  is the field of integers
is the field of integers 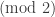 . If we assume, in addition,
. If we assume, in addition,  is the number
is the number  of non-zero coordinates of
of non-zero coordinates of  .
. such that
such that  for all distinct
for all distinct  .
.
 .
.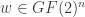 and any
and any 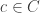 , if
, if  then every
then every 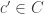 ,
, 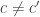 , must satisfy
, must satisfy 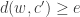 (in other words, there is at most one codeword within distance
(in other words, there is at most one codeword within distance 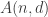 denote the largest possible size of a binary code
denote the largest possible size of a binary code 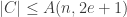 .
.  denote the largest possible size of a binary linear code
denote the largest possible size of a binary linear code 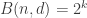 , for some
, for some  .
.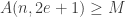 .
. associated to his secret number is, and if he lies
associated to his secret number is, and if he lies  of Hamming distance
of Hamming distance  (or
(or  , where we take
, where we take  , to be more precise) have been tabulated for “small” values of
, to be more precise) have been tabulated for “small” values of  ,
,

You must be logged in to post a comment.