Let f be a Boolean function on  . The Cayley graph of f is defined to be the graph
. The Cayley graph of f is defined to be the graph
 ,
,
whose vertex set is and the set of edges is defined by
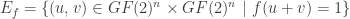 .
.
The adjacency matrix 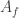 is the matrix whose entries are
is the matrix whose entries are
 ,
,
where b(k) is the binary representation of the integer k.
Note  is a regular graph of degree wt(f), where wt denotes the Hamming weight of f when regarded as a vector of values (of length
is a regular graph of degree wt(f), where wt denotes the Hamming weight of f when regarded as a vector of values (of length 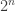 ).
).
Recall that, given a graph  and its adjacency matrix A, the spectrum Spec() is the multi-set of eigenvalues of A.
and its adjacency matrix A, the spectrum Spec() is the multi-set of eigenvalues of A.
The Walsh transform of a Boolean function f is an integer-valued function over that can be defined as

A Boolean function f is bent if 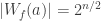 (this only makes sense if n is even). The Hadamard transform of a integer-valued function f is an integer-valued function over that can be defined as
(this only makes sense if n is even). The Hadamard transform of a integer-valued function f is an integer-valued function over that can be defined as

It turns out that the spectrum of is equal to the Hadamard transform of f when regarded as a vector of (integer) 0,1-values. (This nice fact seems to have first appeared in [2], [3].)
A graph is regular of degree r (or r-regular) if every vertex has degree r (number of edges incident to it). We say that an r-regular graph is a strongly regular graph with parameters (v, r, d, e) (for nonnegative integers e, d) provided, for all vertices u, v the number of vertices adjacent to both u, v is equal to
e, if u, v are adjacent,
d, if u, v are nonadjacent.
It turns out tht f is bent iff is strongly regular and e = d (see [3] and [4]).
The following Sage computations illustrate these and other theorems in [1], [2], [3], [4].
Consider the Boolean function  given by
given by  .
.
sage: V = GF(2)^4
sage: f = lambda x: x[0]*x[1]+x[2]*x[3]
sage: CartesianProduct(range(16), range(16))
Cartesian product of [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15],
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15]
sage: C = CartesianProduct(range(16), range(16))
sage: Vlist = V.list()
sage: E = [(x[0],x[1]) for x in C if f(Vlist[x[0]]+Vlist[x[1]])==1]
sage: len(E)
96
sage: E = Set([Set(s) for s in E])
sage: E = [tuple(s) for s in E]
sage: Gamma = Graph(E)
sage: Gamma
Graph on 16 vertices
sage: VG = Gamma.vertices()
sage: L1 = []
sage: L2 = []
sage: for v1 in VG:
....: for v2 in VG:
....: N1 = Gamma.neighbors(v1)
....: N2 = Gamma.neighbors(v2)
....: if v1 in N2:
....: L1 = L1+[len([x for x in N1 if x in N2])]
....: if not(v1 in N2) and v1!=v2:
....: L2 = L2+[len([x for x in N1 if x in N2])]
....:
....:
sage: L1; L2
[2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2]
[2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2]
This implies the graph is strongly regular with d=e=2.
sage: Gamma.spectrum()
[6, 2, 2, 2, 2, 2, 2, -2, -2, -2, -2, -2, -2, -2, -2, -2]
sage: [walsh_transform(f, a) for a in V]
[4, 4, 4, -4, 4, 4, 4, -4, 4, 4, 4, -4, -4, -4, -4, 4]
sage: Omega_f = [v for v in V if f(v)==1]
sage: len(Omega_f)
6
sage: Gamma.is_bipartite()
False
sage: Gamma.is_hamiltonian()
True
sage: Gamma.is_planar()
False
sage: Gamma.is_regular()
True
sage: Gamma.is_eulerian()
True
sage: Gamma.is_connected()
True
sage: Gamma.is_triangle_free()
False
sage: Gamma.diameter()
2
sage: Gamma.degree_sequence()
[6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]
sage: show(Gamma)
# bent-fcns-cayley-graphs1.png
Here is the picture of the graph:

sage: H = matrix(QQ, 16, 16, [(-1)^(Vlist[x[0]]).dot_product(Vlist[x[1]]) for x in C])
sage: H
[ 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1]
[ 1 -1 1 -1 1 -1 1 -1 1 -1 1 -1 1 -1 1 -1]
[ 1 1 -1 -1 1 1 -1 -1 1 1 -1 -1 1 1 -1 -1]
[ 1 -1 -1 1 1 -1 -1 1 1 -1 -1 1 1 -1 -1 1]
[ 1 1 1 1 -1 -1 -1 -1 1 1 1 1 -1 -1 -1 -1]
[ 1 -1 1 -1 -1 1 -1 1 1 -1 1 -1 -1 1 -1 1]
[ 1 1 -1 -1 -1 -1 1 1 1 1 -1 -1 -1 -1 1 1]
[ 1 -1 -1 1 -1 1 1 -1 1 -1 -1 1 -1 1 1 -1]
[ 1 1 1 1 1 1 1 1 -1 -1 -1 -1 -1 -1 -1 -1]
[ 1 -1 1 -1 1 -1 1 -1 -1 1 -1 1 -1 1 -1 1]
[ 1 1 -1 -1 1 1 -1 -1 -1 -1 1 1 -1 -1 1 1]
[ 1 -1 -1 1 1 -1 -1 1 -1 1 1 -1 -1 1 1 -1]
[ 1 1 1 1 -1 -1 -1 -1 -1 -1 -1 -1 1 1 1 1]
[ 1 -1 1 -1 -1 1 -1 1 -1 1 -1 1 1 -1 1 -1]
[ 1 1 -1 -1 -1 -1 1 1 -1 -1 1 1 1 1 -1 -1]
[ 1 -1 -1 1 -1 1 1 -1 -1 1 1 -1 1 -1 -1 1]
sage: flist = vector(QQ, [int(f(v)) for v in V])
sage: H*flist
(6, -2, -2, 2, -2, -2, -2, 2, -2, -2, -2, 2, 2, 2, 2, -2)
sage: A = matrix(QQ, 16, 16, [f(Vlist[x[0]]+Vlist[x[1]]) for x in C])
sage: A.eigenvalues()
[6, 2, 2, 2, 2, 2, 2, -2, -2, -2, -2, -2, -2, -2, -2, -2]
Here is another example:  given by
given by 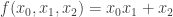 .
.
sage: V = GF(2)^3
sage: f = lambda x: x[0]*x[1]+x[2]
sage: Omega_f = [v for v in V if f(v)==1]
sage: len(Omega_f)
4
sage: C = CartesianProduct(range(8), range(8))
sage: Vlist = V.list()
sage: E = [(x[0],x[1]) for x in C if f(Vlist[x[0]]+Vlist[x[1]])==1]
sage: E = Set([Set(s) for s in E])
sage: E = [tuple(s) for s in E]
sage: Gamma = Graph(E)
sage: Gamma
Graph on 8 vertices
sage:
sage: VG = Gamma.vertices()
sage: L1 = []
sage: L2 = []
sage: for v1 in VG:
....: for v2 in VG:
....: N1 = Gamma.neighbors(v1)
....: N2 = Gamma.neighbors(v2)
....: if v1 in N2:
....: L1 = L1+[len([x for x in N1 if x in N2])]
....: if not(v1 in N2) and v1!=v2:
....: L2 = L2+[len([x for x in N1 if x in N2])]
....:
sage: L1; L2
[2, 0, 2, 2, 2, 2, 0, 2, 2, 2, 0, 2, 2, 2, 2, 0, 0, 2, 2, 2, 2, 0, 2, 2, 2, 0, 2, 2, 2, 2, 0, 2]
[2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2]
This implies that the graph is not strongly regular, therefore f is not bent.
sage: Gamma.spectrum()
[4, 2, 0, 0, 0, -2, -2, -2]
sage:
sage: Gamma.is_bipartite()
False
sage: Gamma.is_hamiltonian()
True
sage: Gamma.is_planar()
False
sage: Gamma.is_regular()
True
sage: Gamma.is_eulerian()
True
sage: Gamma.is_connected()
True
sage: Gamma.is_triangle_free()
False
sage: Gamma.diameter()
2
sage: Gamma.degree_sequence()
[4, 4, 4, 4, 4, 4, 4, 4]
sage: H = matrix(QQ, 8, 8, [(-1)^(Vlist[x[0]]).dot_product(Vlist[x[1]]) for x in C])
sage: H
[ 1 1 1 1 1 1 1 1]
[ 1 -1 1 -1 1 -1 1 -1]
[ 1 1 -1 -1 1 1 -1 -1]
[ 1 -1 -1 1 1 -1 -1 1]
[ 1 1 1 1 -1 -1 -1 -1]
[ 1 -1 1 -1 -1 1 -1 1]
[ 1 1 -1 -1 -1 -1 1 1]
[ 1 -1 -1 1 -1 1 1 -1]
sage: flist = vector(QQ, [int(f(v)) for v in V])
sage: H*flist
(4, 0, 0, 0, -2, -2, -2, 2)
sage: Gamma.spectrum()
[4, 2, 0, 0, 0, -2, -2, -2]
sage: A = matrix(QQ, 8, 8, [f(Vlist[x[0]]+Vlist[x[1]]) for x in C])
sage: A.eigenvalues()
[4, 2, 0, 0, 0, -2, -2, -2]
sage: show(Gamma)
# bent-fcns-cayley-graphs2.png
Here is the picture:

REFERENCES:
[1] Pantelimon Stanica, Graph eigenvalues and Walsh spectrum of Boolean functions, INTEGERS 7(2) (2007), #A32.
[2] Anna Bernasconi, Mathematical techniques for the analysis of Boolean functions, Ph. D. dissertation TD-2/98, Universit di Pisa-Udine, 1998.
[3] Anna Bernasconi and Bruno Codenotti, Spectral Analysis of Boolean Functions as a Graph Eigenvalue Problem, IEEE TRANSACTIONS ON COMPUTERS, VOL. 48, NO. 3, MARCH 1999.
[4] A. Bernasconi, B. Codenotti, J.M. VanderKam. A Characterization of Bent Functions in terms of Strongly Regular Graphs, IEEE Transactions on Computers, 50:9 (2001), 984-985.
[5] Michel Mitton, Minimal polynomial of Cayley graph adjacency matrix for Boolean functions, preprint, 2007.
[6] ——, On the Walsh-Fourier analysis of Boolean functions, preprint, 2006.


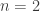

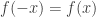
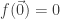








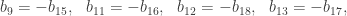
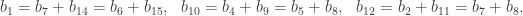



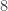

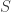

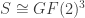

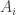 on the vector of water quantities, indexed by the students. I think that in general the answer to Q1 is “yes.” Here is the Sage code in the case of 3 students:
on the vector of water quantities, indexed by the students. I think that in general the answer to Q1 is “yes.” Here is the Sage code in the case of 3 students: has eigenvalue
has eigenvalue  with eigenvector
with eigenvector 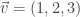 . This means that in the case that student 1 has 3 ounces of water, student 2 has 2 ounces of water, student 3 has 1 ounce of water, if each student shares water as explained in the problem, at the end of the process, they will each have the same amount as they started with.
. This means that in the case that student 1 has 3 ounces of water, student 2 has 2 ounces of water, student 3 has 1 ounce of water, if each student shares water as explained in the problem, at the end of the process, they will each have the same amount as they started with. , we may identify a Boolean function
, we may identify a Boolean function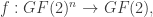
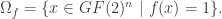
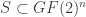 , let
, let 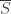 denote the set of complements
denote the set of complements  , for
, for  , and let
, and let 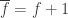 denote the complementary Boolean function. Note that
denote the complementary Boolean function. Note that
 denotes the complement of
denotes the complement of 
 is even (resp., odd). We may identify a vector in
is even (resp., odd). We may identify a vector in  Let
Let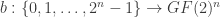
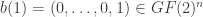 ).
).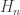 denote the $2^n\times 2^n$ Hadamard matrix defined by
denote the $2^n\times 2^n$ Hadamard matrix defined by 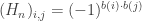 , for each
, for each 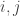 such that
such that 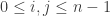 . Inductively, these can be defined by
. Inductively, these can be defined by
 whose
whose 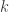 th component is
th component is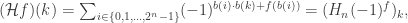
 as the column vector where the
as the column vector where the 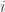 th component is
th component is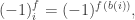
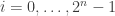 .
.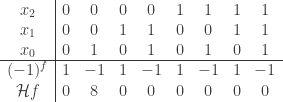
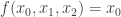 . It is even because
. It is even because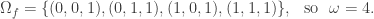
 be the Cayley graph of
be the Cayley graph of 
 so
so 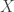 has no loops. In this case,
has no loops. In this case,  -regular graph having
-regular graph having  connected components, where
connected components, where
 , the set of neighbors
, the set of neighbors  of
of  is given by
is given by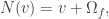
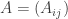 be the
be the 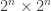 adjacency matrix of
adjacency matrix of 

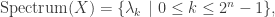
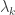 of the adjacency matrix
of the adjacency matrix 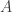 ) to the Walsh-Hadamard transform
) to the Walsh-Hadamard transform 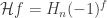 . Note that
. Note that  where
where 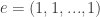 . She discovered the relationship
. She discovered the relationship
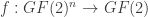 be a Boolean function. (We identify
be a Boolean function. (We identify  with either the real numbers
with either the real numbers 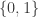 or the binary field
or the binary field  . Hopefully, the context makes it clear which one is used.)
. Hopefully, the context makes it clear which one is used.) on
on  , we say
, we say 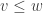 whenever we have
whenever we have 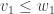 ,
,  , …,
, …, 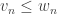 . A Boolean function is called monotone (increasing) if whenever we have
. A Boolean function is called monotone (increasing) if whenever we have 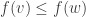 .
. 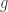 are monotone then (a)
are monotone then (a)  is also monotone, and (b)
is also monotone, and (b)  . (Overline means bit-wise complement.)
. (Overline means bit-wise complement.) is the least support of
is the least support of 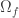 which are smallest in the partial ordering
which are smallest in the partial ordering  on
on  ,
, 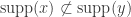 and
and 


 .
. . Then
. Then

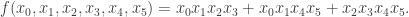
 .
.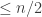 ?
?
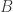 are matrices of the same size. Then
are matrices of the same size. Then 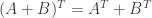 .
.
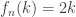 , if k <= n/2 and
, if k <= n/2 and  , if
, if  Let
Let  , where
, where 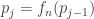 and
and 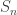 is the symmetric group of order
is the symmetric group of order 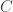 be the binary Hamming [7,4,3] code defined by the generator matrix
be the binary Hamming [7,4,3] code defined by the generator matrix 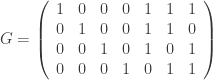 and check matrix
and check matrix 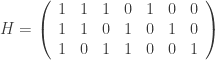 . In other words, this code is the row space of G and the kernel of H. We can enter these into Sage as follows:
. In other words, this code is the row space of G and the kernel of H. We can enter these into Sage as follows: defined by
defined by 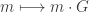 . Using this map, the codewords are easy to describe and enumerate:
. Using this map, the codewords are easy to describe and enumerate: .
.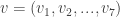 . This must be a codeword (no lies) or differ from a codeword by exactly one bit (1 lie). In either case, you can find n by decoding this vector.
. This must be a codeword (no lies) or differ from a codeword by exactly one bit (1 lie). In either case, you can find n by decoding this vector.
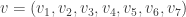 .
.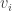 in region i of the Venn diagram.
in region i of the Venn diagram.






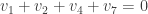
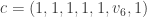 , for some unknown
, for some unknown  . We solve for this unknown using the check vertex equation
. We solve for this unknown using the check vertex equation  . The decoded codeword is
. The decoded codeword is 
 . In this case, we know the vertices 9 and 10 fail, so
. In this case, we know the vertices 9 and 10 fail, so  . We solve using
. We solve using 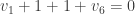

 . By majority vote, we get
. By majority vote, we get  .
.  is its length,
is its length,  is its dimension, and
is its dimension, and 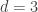 is its minimum distance),
is its minimum distance), 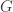 is a generating matrix,
is a generating matrix,  is a check matrix, and
is a check matrix, and 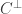 is the dual code of
is the dual code of 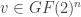 to be a cover, and the message
to be a cover, and the message  we embed is an element of
we embed is an element of  . Once we find a vector
. Once we find a vector  of lowest weight such that
of lowest weight such that 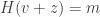 , we call
, we call  the stegocover. The stegocover looks a lot like the original cover and “contains” the message m. This will be explained in more detai below.
the stegocover. The stegocover looks a lot like the original cover and “contains” the message m. This will be explained in more detai below. is an integer called the length of the code. Moreover, the basis for the ambient space
is an integer called the length of the code. Moreover, the basis for the ambient space 
 are the rows of
are the rows of 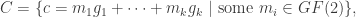
 . The vector of coefficients,
. The vector of coefficients,  represents the information you want to encode and transmit.
represents the information you want to encode and transmit.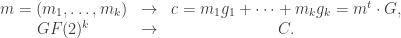
 . This matrix is called a check matrix of
. This matrix is called a check matrix of 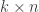 matrix then a full rank check matrix
matrix then a full rank check matrix 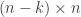 matrix.
matrix.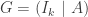 is the generating matrix for
is the generating matrix for  is a parity check matrix.
is a parity check matrix. be an integer and let
be an integer and let  matrix whose columns are all the distinct non-zero vectors of
matrix whose columns are all the distinct non-zero vectors of  , and let
, and let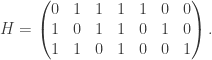
 entries is the identity matrix
entries is the identity matrix 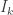 , the generator matrix
, the generator matrix 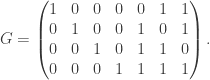
 is a subset of
is a subset of  for some
for some  . Let
. Let  .
.
 is a set of all possible covers
is a set of all possible covers
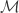 is a set of all possible messages
is a set of all possible messages
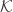 is a set of all possible keys
is a set of all possible keys
 is an embedding function
is an embedding function
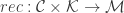 is a recovery function
is a recovery function

 ,
,  ,
,  . We will assume that a fixed key
. We will assume that a fixed key  is called the plain cover,
is called the plain cover,  is called the stegocover. Let
is called the stegocover. Let  , where
, where 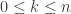 .
.  and consider the cover
and consider the cover  . Regarded as a
. Regarded as a  matrix,
matrix, 
 . First we compute the stegocover:
. First we compute the stegocover:



You must be logged in to post a comment.